
要約
バックエンド開発者のためのメッセージキュー入門 2026
現代のバックエンドシステムに不可欠なメッセージキューの基本から、Kafka, RabbitMQ, AWS SQSの主要3サービスを徹底比較し、実践的な活用法まで解説します。
Keywords: メッセージキュー, Kafka, RabbitMQ
目次
1. 背景と導入:なぜ今、メッセージキューが重要なのか?
2. メッセージキューの基本概念
3. 主要メッセージキューサービス徹底比較 2026
4. 実践的な活用法と実装例
5. よくある課題と解決策
6. よくある質問 (FAQ)
7. まとめと今後の展望
1. 背景と導入:なぜ今、メッセージキューが重要なのか?
現代のWebサービスやアプリケーションは、かつてないほど複雑化し、ユーザーからの要求も多様化しています。マイクロサービスアーキテクチャの普及、IoTデバイスの増加、リアルタイムデータ処理の必要性など、システムが処理すべきデータ量とトランザクション数は爆発的に増加しています。このような状況下で、従来の同期的な処理モデルだけでは、システムのスケーラビリティ、可用性、そして信頼性を維持することが極めて困難になっています。
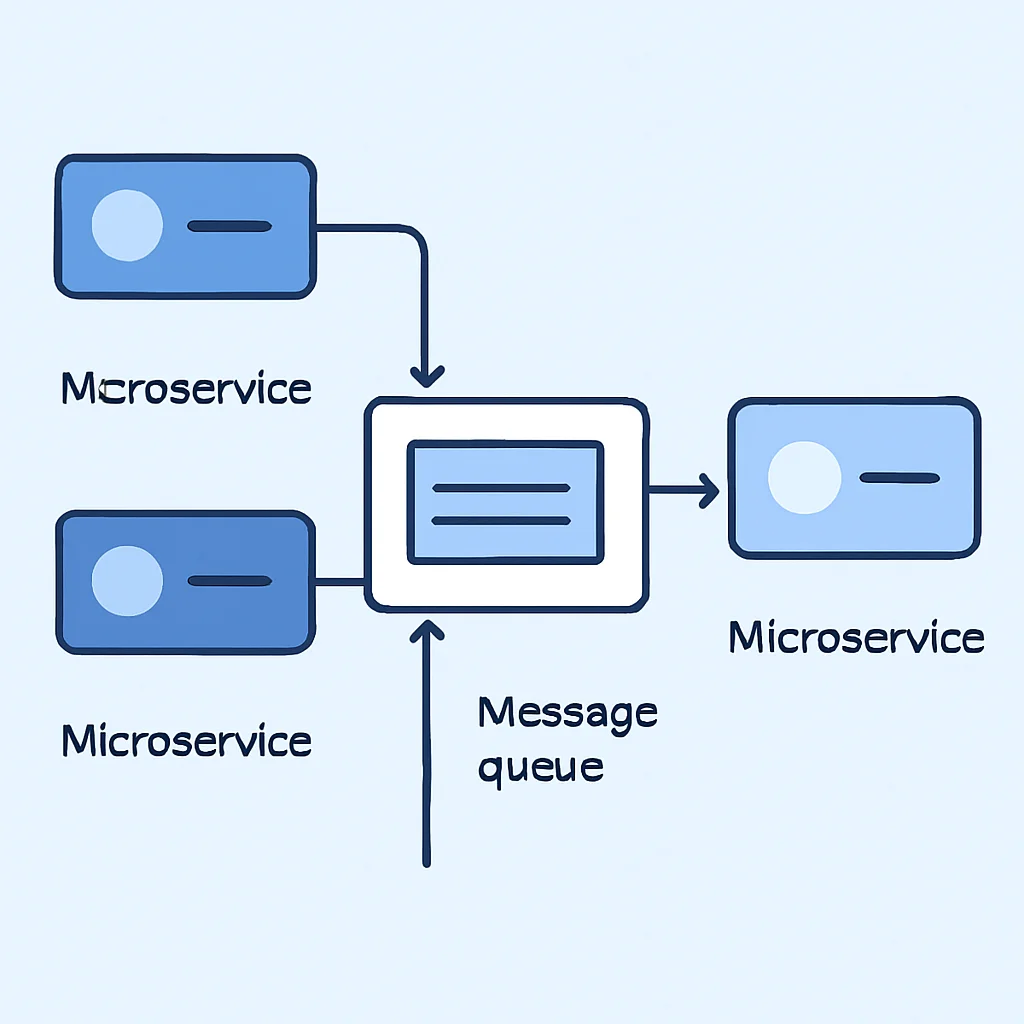
ここで注目されるのが「メッセージキュー」です。メッセージキューは、アプリケーション間でメッセージ(データ)を非同期にやり取りするための仕組みを提供します。これにより、送信側と受信側が直接通信することなく、メッセージブローカーを介して疎結合なシステムを構築できます。これは、特に高負荷な処理や時間のかかる処理をバックグラウンドで実行する際に、ユーザー体験を損なうことなくシステム全体の応答性を向上させる上で不可欠な要素となります。
例えば、ユーザーがECサイトで商品を注文したとします。この注文処理には、在庫の引き落とし、決済処理、注文履歴の更新、配送手配、確認メールの送信など、複数のステップが含まれます。これらの処理をすべて同期的に行うと、どこか一つの処理が遅延するだけで、ユーザーは次の画面に進むまでに長い時間待たされることになります。しかし、メッセージキューを利用すれば、注文を受け付けた時点で「注文メッセージ」をキューに発行し、個々の処理はメッセージを消費して非同期に実行できます。これにより、ユーザーは注文完了画面にすぐに遷移でき、裏側で複雑な処理が並行して進むため、システム全体のパフォーマンスとユーザー満足度が向上します。
2026年現在、クラウドネイティブな開発が主流となり、コンテナ技術やサーバーレスアーキテクチャが一般的になる中で、メッセージキューは分散システムの基盤としてその重要性をさらに増しています。本記事では、バックエンド開発者がメッセージキューを効果的に活用するために、その基本概念から、代表的なサービスであるKafka、RabbitMQ、AWS SQSの特性を徹底的に比較し、具体的な実装例と課題解決策までを深く掘り下げていきます。
ポイント
メッセージキューは、現代の分散システムにおいて、非同期処理、疎結合、スケーラビリティ、そして障害耐性を実現するための不可欠なコンポーネントです。特に、高負荷な処理や複雑なワークフローを持つシステムで真価を発揮します。
2. メッセージキューの基本概念
メッセージキューの具体的なサービスを比較する前に、まずはその基盤となる概念をしっかりと理解しておくことが重要です。メッセージキューシステムは、いくつかの主要なコンポーネントと概念で構成されています。
メッセージ、プロデューサー、コンシューマー
メッセージ (Message): システム間でやり取りされるデータの最小単位です。通常、JSONやProtocol Buffersなどの形式でエンコードされたペイロードと、ルーティング情報やメタデータ(タイムスタンプ、メッセージIDなど)を含みます。
プロデューサー (Producer): メッセージをキューに送信するアプリケーションやサービスです。メッセージの送信後、プロデューサーは通常、そのメッセージが処理されるのを待たずに次のタスクに進みます。
コンシューマー (Consumer): キューからメッセージを受信し、処理するアプリケーションやサービスです。コンシューマーは通常、キューをポーリングするか、ブローカーからのプッシュ通知を受けてメッセージを取得します。メッセージ処理が完了すると、コンシューマーはブローカーにその旨を通知(ACK)します。
キューとブローカー
キュー (Queue): プロデューサーから送信されたメッセージが一時的に格納される場所です。一般的にはFIFO (First-In, First-Out) 形式でメッセージが保持されますが、優先度付きキューや、特定のルールに基づいてルーティングされるキューも存在します。
ブローカー (Broker): メッセージキューシステムの中核をなすサーバーまたはサービスです。プロデューサーからのメッセージを受け取り、キューに格納し、コンシューマーにメッセージを配信する役割を担います。ブローカーはメッセージの永続性、ルーティング、負荷分散などを管理します。
同期処理と非同期処理
同期処理: リクエストを送信した後、レスポンスが返ってくるまで処理がブロックされる方式です。シンプルで実装しやすい反面、処理に時間がかかるとシステム全体の応答性が低下し、タイムアウトやリソース枯渇のリスクがあります。
非同期処理: リクエストを送信した後、レスポンスを待たずに次の処理に進む方式です。メッセージキューはこの非同期処理を実現する主要な手段です。プロデューサーはメッセージをキューに送信したらすぐに解放され、コンシューマーがバックグラウンドでメッセージを処理します。これにより、システムの応答性が向上し、コンソースの効率的な利用が可能になります。
メッセージ配信のセマンティクス
メッセージキューシステムでは、メッセージがどのように配信されるかに関して、主に以下の3つのセマンティクスがあります。
At-most-once (最大1回): メッセージは最大で1回だけ配信されます。メッセージの重複は発生しませんが、ネットワーク障害などによりメッセージが失われる可能性があります。パフォーマンスが最優先で、メッセージ損失が許容される場合に適しています。
At-least-once (最低1回): メッセージは最低1回は配信されます。メッセージが失われることはありませんが、ネットワーク障害やコンシューマーの再起動などにより、メッセージが複数回配信される(重複する)可能性があります。ほとんどのビジネスロジックでこの保証が求められ、重複処理対策(冪等性)が必要になります。
Exactly-once (正確に1回): メッセージは正確に1回だけ配信されます。最も強力な保証ですが、実装が非常に複雑で、パフォーマンスへの影響も大きくなります。分散トランザクションや金融システムなど、厳密な整合性が求められるケースで利用されますが、多くのメッセージキューシステムでは完全な「Exactly-once」の実現は困難であり、At-least-onceと冪等性処理の組み合わせで代替されることが多いです。
ポイント
メッセージキューの基本要素(メッセージ、プロデューサー、コンシューマー、キュー、ブローカー)と、非同期処理のメリット、そしてメッセージ配信セマンティクス(At-most-once, At-least-once, Exactly-once)の違いを理解することは、適切なメッセージキューを選択し、堅牢なシステムを設計する上で不可欠です。
3. 主要メッセージキューサービス徹底比較 2026
ここでは、バックエンド開発で最もよく利用される3つのメッセージキューサービス、Apache Kafka、RabbitMQ、AWS SQSについて、2026年現在の最新情報を踏まえて徹底的に比較分析します。それぞれの特徴、得意なユースケース、メリット・デメリットを深く掘り下げ、システム要件に応じた最適な選択をサポートします。
3.1. Apache Kafka
Kafkaは、LinkedInによって開発され、後にApacheソフトウェア財団に寄贈された分散ストリーミングプラットフォームです。単なるメッセージキューではなく、高スループットでのイベントログの永続化、リアルタイムストリーム処理、およびイベントソーシングを目的として設計されています。メッセージは「トピック」と呼ばれるカテゴリに分類され、トピックはさらに「パーティション」に分割されます。各パーティションは順序付けされた変更ログとして機能し、メッセージはオフセットと呼ばれる一意のIDで識別されます。
主な特徴:
- 高スループットとスケーラビリティ: 数百万メッセージ/秒を処理できる設計であり、水平スケーリングが容易です。
- 永続性: メッセージは設定された期間(通常は数日〜数週間)ディスクに保存されるため、コンシューマーはいつでも過去のメッセージを再読み込みできます。
- 分散型: 複数のブローカー(ノード)で構成され、高い可用性と耐障害性を持ちます。ZooKeeper(またはKRaftモードではKafka自身)がクラスタの状態管理を行います。
- コンシューマーグループ: 複数のコンシューマーが協力してトピックのパーティションを消費することで、負荷分散と並列処理を実現します。
得意なユースケース:
- ログ収集と監視: 多数のサーバーからリアルタイムでログやメトリクスを収集し、集中管理システムに送る。
- リアルタイムデータ処理: ストリームデータ(クリックストリーム、センサーデータなど)をリアルタイムで分析し、ダッシュボード表示や異常検知を行う。
- イベントソーシング: システム内のすべての状態変更をイベントとして記録し、永続的なイベントログを構築する。
- マイクロサービス間通信: 大量のイベントを伴うサービス間の非同期通信基盤。
メリット
✓ 非常に高いスループットと水平スケーラビリティ。
✓ メッセージの永続性により、過去のデータを再処理可能。
✓ 多数のコンシューマーが独立して同じデータを消費できる。
デメリット
✗ 運用・管理が複雑で、専門知識が必要(特にオンプレミスの場合)。
✗ メッセージの厳密な順序保証はパーティション内のみ。
✗ メッセージのルーティング機能は比較的シンプル。
ポイント
Kafkaは、大量のイベントストリームをリアルタイムで処理・永続化する必要があるシステムに最適です。その分散性とスケーラビリティは、ビッグデータやイベントドリブンアーキテクチャの基盤として非常に強力です。
3.2. RabbitMQ
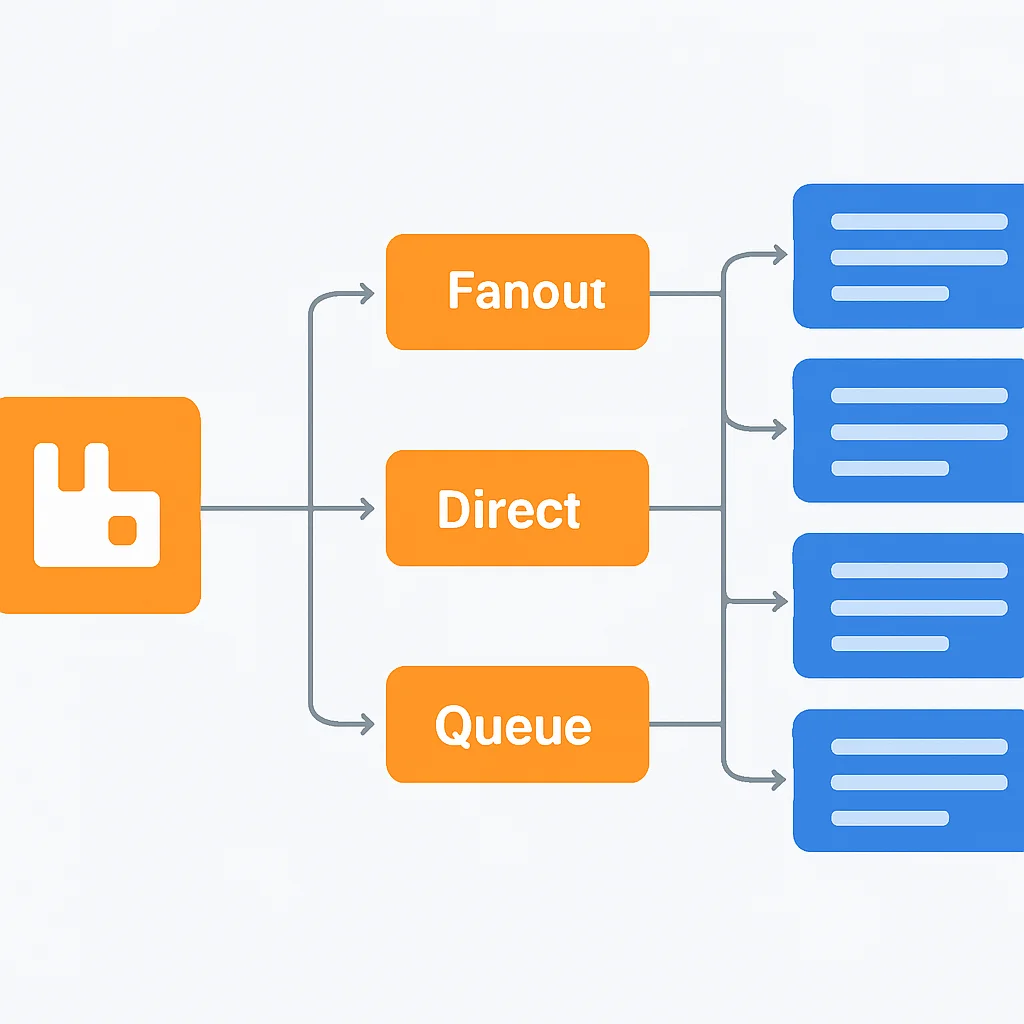
RabbitMQは、AMQP (Advanced Message Queuing Protocol) を実装したオープンソースのメッセージブローカーです。その特徴は、柔軟で高度なルーティング機能にあります。メッセージは「エクスチェンジ」に送信され、エクスチェンジは定義されたルール(バインディング)に基づいてメッセージを1つまたは複数の「キュー」にルーティングします。これにより、複雑なメッセージ配信パターンを容易に実現できます。
主な特徴:
- 高度なルーティング: Direct, Fanout, Topic, Headersといった多様なエクスチェンジタイプにより、柔軟なメッセージルーティングが可能です。
- AMQPプロトコル: 標準プロトコルに基づいているため、異なる言語やプラットフォーム間での互換性が高いです。
- メッセージの信頼性: メッセージの永続化、発行者確認 (publisher confirms)、コンシューマー確認 (consumer acknowledgements) などの機能により、高い信頼性を確保します。
- 使いやすさ: 管理UIが提供されており、キューの状態監視や管理が比較的容易です。
得意なユースケース:
- タスクキューとワークフロー: 長時間かかるタスク(画像処理、メール送信、レポート生成など)をバックグラウンドで処理する。
- 複雑なルーティング要件: 特定の条件に基づいてメッセージを複数のコンシューマーに配信したり、異なるサービスにルーティングしたりする場合。
- マイクロサービス間通信: 疎結合なサービス間で、比較的少量の、しかし確実に配信されるべきメッセージをやり取りする。
- 通知システム: ユーザーへの通知(プッシュ通知、SMSなど)を非同期に送信する。
メリット
✓ 柔軟なメッセージルーティング機能。
✓ メッセージの配信信頼性が高い。
✓ 比較的容易な運用管理(特に小〜中規模)。
デメリット
✗ 非常に高いスループットのシナリオではKafkaに劣る。
✗ メッセージが消費されるとキューから削除されるため、過去のメッセージを再処理しにくい。
✗ 長期的なメッセージ永続性には不向き。
ポイント
RabbitMQは、メッセージの信頼性と複雑なルーティングが求められる、タスクキューやワークフロー管理システムに強みを発揮します。Kafkaのような超高スループットは不要だが、柔軟なメッセージ配信が必要な場合に適しています。
3.3. AWS SQS (Simple Queue Service)
AWS SQSは、Amazonが提供するフルマネージド型のメッセージキューサービスです。サーバーのプロビジョニングやパッチ適用、メンテナンスが不要なため、運用負担が極めて低いのが最大の魅力です。メッセージキューの基本機能に特化しており、シンプルなAPIで利用できます。
主な特徴:
- フルマネージドかつサーバーレス: インフラ管理が不要で、利用量に応じた従量課金。
- 高いスケーラビリティと可用性: AWSのインフラ上で自動的にスケーリングし、高い可用性を実現。
- 2種類のキュー:
- 標準キュー (Standard Queue): ほぼ無制限のスループットを提供しますが、メッセージの順序保証や重複排除は保証されません(At-least-once配信)。
- FIFOキュー (First-In, First-Out Queue): メッセージの厳密な順序保証と、メッセージの重複排除(At-most-once配信)を提供します。スループットは標準キューより低いですが、多くのユースケースで十分な性能を発揮します。
- 可視性タイムアウト (Visibility Timeout): コンシューマーがメッセージを処理している間、他のコンシューマーが同じメッセージを消費しないように一時的に非表示にする仕組み。
- デッドレターキュー (DLQ) 対応: 処理に失敗したメッセージを自動的に別のキューに転送する機能。
得意なユースケース:
- マイクロサービス間通信: 疎結合なサービス間での非同期メッセージング。
- 非同期タスク処理: Webリクエストの応答性を高めるためのバックグラウンドタスク(画像リサイズ、動画エンコードなど)。
- ファンアウトパターン: 1つのメッセージを複数のコンシューマーに配信する(AWS SNSと連携)。
- サーバーレスアーキテクチャ: AWS Lambdaと組み合わせることで、イベントドリブンな処理を容易に構築。
メリット
✓ 運用管理が不要なフルマネージドサービス。
✓ 高いスケーラビリティと可用性。
✓ 従量課金制でコスト効率が良い。
デメリット
✗ メッセージの長期的な永続性には不向き(最大14日)。
✗ メッセージのルーティング機能は比較的シンプルで、複雑なパターンにはAWS SNSなど他のサービスとの組み合わせが必要。
✗ クラウドベンダーロックインのリスクがある。
ポイント
AWS SQSは、運用負担を最小限に抑えつつ、高いスケーラビリティと可用性を持つメッセージキューを迅速に導入したい場合に最適です。特にAWSエコシステム内でサーバーレスアーキテクチャを構築する際には非常に強力な選択肢となります。
3.4. 主要メッセージキューサービス比較表 2026
これまでに解説した3つのサービスを、主要な観点から比較した表を以下に示します。これにより、各サービスの特徴がより明確になるでしょう。
| 項目 | Apache Kafka | RabbitMQ | AWS SQS |
|---|---|---|---|
| タイプ | 分散ストリーミングプラットフォーム | 汎用メッセージブローカー | フルマネージドメッセージキュー |
| スループット | 非常に高い(数百万メッセージ/秒) | 中〜高(数万〜数十万メッセージ/秒) | 非常に高い(標準キュー)、中(FIFOキュー) |
| メッセージ永続性 | 長期(数日〜数週間/年)、ログベース | 中程度(消費されるまで、ディスク永続化オプションあり) | 短期(最大14日) |
| ルーティング機能 | シンプル(トピックベース、パーティション) | 高度で柔軟(エクスチェンジ、バインディング、ルーティングキー) | シンプル(キューベース)、SNSと連携でファンアウト |
| 順序保証 | パーティション内のみ | キュー内での厳密な保証 | 標準キュー: なし / FIFOキュー: 厳密な保証 |
| 重複メッセージ | At-least-once (コンシューマー側で冪等性が必要) | At-least-once (コンシューマー側で冪等性が必要) | 標準キュー: At-least-once / FIFOキュー: At-most-once |
| 運用・管理 | 複雑(専門知識、クラスタ管理) | 中程度(クラスタ管理、設定) | 非常に容易(フルマネージド) |
| コストモデル | インフラ費用(OSS)またはマネージドサービス費用 | インフラ費用(OSS)またはマネージドサービス費用 | 従量課金制(メッセージ数、データ転送量) |
3.5. どのメッセージキューを選ぶべきか?
上記の比較を踏まえ、あなたのプロジェクトに最適なメッセージキューを選択するためのガイドラインをいくつか提示します。
-
Kafkaが最適なケース:
- 毎秒数十万〜数百万のイベントを処理する超高スループット要件。
- リアルタイム分析、イベントソーシング、ストリーム処理が中心。
- メッセージの長期的な永続性が必要で、過去のデータを何度も再処理する可能性がある。
- 運用チームに分散システムの専門知識がある、またはマネージドKafkaサービス(AWS MSK, Confluent Cloudなど)を利用する。
-
RabbitMQが最適なケース:
- 複雑なメッセージルーティングロジックが必要(例: 特定の条件でメッセージを異なるサービスに配信)。
- タスクキュー、ワークフロー管理、通知システムなど、メッセージの確実な配信と順序保証(キュー内)が重要。
- AMQPプロトコルなどの標準プロトコルへの準拠が求められる。
- 高スループットよりも、柔軟性と信頼性が重視される。
-
AWS SQSが最適なケース:
- インフラの運用・管理コストを最小限に抑えたい。
- AWSエコシステム内でサービスを構築しており、他のAWSサービス(Lambda, SNSなど)との連携を重視する。
- シンプルな非同期メッセージング、マイクロサービス間通信、ファンアウトパターンが主なユースケース。
- メッセージの長期永続性は不要(最大14日)。
- 厳密な順序保証が必要な場合はFIFOキューを選択する。
注意
どのメッセージキューも万能ではありません。システムの要件(スループット、永続性、ルーティングの複雑さ、運用コスト、既存インフラなど)を総合的に評価し、最適な選択を行うことが重要です。また、単一のシステム内で複数のメッセージキューを使い分けるハイブリッドアプローチも有効な場合があります。
4. 実践的な活用法と実装例
ここでは、それぞれのメッセージキューを実際にどのように利用するか、具体的なコード例を交えながら解説します。プロデューサーとコンシューマーの基本的な実装パターンに焦点を当てます。
4.1. Go言語でのKafkaプロデューサー/コンシューマー例
Go言語は、その並行処理能力と高いパフォーマンスからバックエンド開発で人気があります。Kafkaクライアントライブラリとしては、confluent-kafka-go や segmentio/kafka-go などがよく使われます。ここではシンプルな例として segmentio/kafka-go を使用します。
コード解説
このGo言語のコードは、Kafkaのプロデューサーとコンシューマーの基本的な実装を示しています。プロデューサーは指定されたトピックにメッセージを書き込み、コンシューマーは同じトピックからメッセージを読み取ります。プロデューサーは非同期でメッセージを送信し、エラーチャネルで結果を受け取ります。コンシューマーは無限ループでメッセージをポーリングし、処理後にコミットします。Kafkaブローカーのアドレスとトピック名を環境変数から取得するようにしています。
package main
import (
"context"
"fmt"
"log"
"os"
"strconv"
"time"
kafka "github.com/segmentio/kafka-go"
)
const (
topic = "my-kafka-topic"
brokerAddress = "localhost:9092" // 本番環境では環境変数から取得
)
func main() {
// Kafkaブローカーアドレスを環境変数から取得
kafkaBroker := os.Getenv("KAFKA_BROKER_ADDRESS")
if kafkaBroker == "" {
kafkaBroker = brokerAddress
}
// プロデューサーの起動
go runKafkaProducer(kafkaBroker, topic)
// コンシューマーの起動
runKafkaConsumer(kafkaBroker, topic)
}
func runKafkaProducer(broker string, topic string) {
writer := kafka.NewWriter(kafka.WriterConfig{
Brokers: []string{broker},
Topic: topic,
Balancer: &kafka.LeastBytes{},
})
defer writer.Close()
fmt.Println("Kafka Producer started. Sending messages...")
for i := 0; i < 10; i++ {
msg := fmt.Sprintf("Hello Kafka from Go! Message %d", i)
err := writer.WriteMessages(context.Background(),
kafka.Message{
Key: []byte(strconv.Itoa(i)),
Value: []byte(msg),
},
)
if err != nil {
log.Printf("Failed to write message: %v", err)
} else {
fmt.Printf("Producer sent message: %s\n", msg)
}
time.Sleep(1 * time.Second)
}
fmt.Println("Kafka Producer finished sending messages.")
}
func runKafkaConsumer(broker string, topic string) {
reader := kafka.NewReader(kafka.ReaderConfig{
Brokers: []string{broker},
Topic: topic,
GroupID: "my-consumer-group", // コンシューマーグループID
MinBytes: 10e3, // 10KB
MaxBytes: 10e6, // 10MB
MaxWait: 1 * time.Second, // 最大1秒待機
})
defer reader.Close()
fmt.Println("Kafka Consumer started. Waiting for messages...")
for {
m, err := reader.ReadMessage(context.Background())
if err != nil {
log.Printf("Error reading message: %v", err)
break
}
fmt.Printf("Consumer received message: Topic=%s, Partition=%d, Offset=%d, Key=%s, Value=%s\n",
m.Topic, m.Partition, m.Offset, string(m.Key), string(m.Value))
// ここでメッセージの処理を行う
// 例: time.Sleep(500 * time.Millisecond)
// メッセージのコミット(処理完了をKafkaに通知)
// reader.CommitMessages(context.Background(), m) // 自動コミットを無効にしている場合
}
fmt.Println("Kafka Consumer stopped.")
}
4.2. PythonでのRabbitMQプロデューサー/コンシューマー例
Pythonは、スクリプト作成やWebアプリケーション開発で広く利用されており、RabbitMQクライアントライブラリとして最も一般的なのは pika です。ここでは、Direct Exchange を使用した基本的なメッセージングの例を示します。
コード解説
このPythonコードは、RabbitMQのプロデューサーとコンシューマーの例です。プロデューサーは指定されたルーティングキーを持つメッセージをエクスチェンジに送信し、コンシューマーは同じルーティングキーを持つキューにバインドしてメッセージを受信します。コンシューマーはメッセージを受信後、処理が完了したことをRabbitMQに確認応答(ACK)します。これにより、メッセージが確実に処理されたことが保証されます。
# producer.py
import pika
import time
import os
RABBITMQ_HOST = os.getenv("RABBITMQ_HOST", "localhost")
EXCHANGE_NAME = "my_direct_exchange"
QUEUE_NAME = "my_queue"
ROUTING_KEY = "info"
def run_producer():
connection = pika.BlockingConnection(pika.ConnectionParameters(host=RABBITMQ_HOST))
channel = connection.channel()
channel.exchange_declare(exchange=EXCHANGE_NAME, exchange_type='direct')
for i in range(10):
message = f"Hello RabbitMQ from Python! Message {i}"
channel.basic_publish(
exchange=EXCHANGE_NAME,
routing_key=ROUTING_KEY,
body=message
)
print(f" [x] Sent '{message}'")
time.sleep(1)
connection.close()
if __name__ == '__main__':
print("RabbitMQ Producer started. Sending messages...")
run_producer()
print("RabbitMQ Producer finished sending messages.")
# consumer.py
import pika
import time
import os
RABBITMQ_HOST = os.getenv("RABBITMQ_HOST", "localhost")
EXCHANGE_NAME = "my_direct_exchange"
QUEUE_NAME = "my_queue"
ROUTING_KEY = "info"
def callback(ch, method, properties, body):
print(f" [x] Received '{body.decode()}'")
# ここでメッセージの処理を行う
time.sleep(2) # 処理に時間がかかることをシミュレート
ch.basic_ack(delivery_tag=method.delivery_tag) # 処理完了をRabbitMQに通知
def run_consumer():
connection = pika.BlockingConnection(pika.ConnectionParameters(host=RABBITMQ_HOST))
channel = connection.channel()
channel.exchange_declare(exchange=EXCHANGE_NAME, exchange_type='direct')
# durable=True でRabbitMQが再起動してもキューが保持される
result = channel.queue_declare(queue=QUEUE_NAME, durable=True)
queue_name = result.method.queue
channel.queue_bind(
exchange=EXCHANGE_NAME,
queue=queue_name,
routing_key=ROUTING_KEY
)
print(' [*] RabbitMQ Consumer started. Waiting for messages. To exit press CTRL+C')
channel.basic_consume(
queue=queue_name,
on_message_callback=callback,
auto_ack=False # 自動確認応答を無効にし、手動でACKを送信
)
channel.start_consuming()
if __name__ == '__main__':
try:
run_consumer()
except KeyboardInterrupt:
print('Interrupted')
try:
sys.exit(0)
except SystemExit:
os._exit(0)
4.3. Node.jsでのAWS SQSプロデューサー/コンシューマー例
Node.jsは、JavaScriptをサーバーサイドで実行できる環境であり、AWS SDKを利用してAWS SQSと簡単に連携できます。ここでは、AWS SDK v3 (@aws-sdk/client-sqs) を使用した例を示します。
コード解説
このNode.jsコードは、AWS SQSのプロデューサーとコンシューマーの基本的な実装です。プロデューサーは SendMessageCommand を使ってキューにメッセージを送信します。コンシューマーは ReceiveMessageCommand を使ってキューからメッセージをポーリングし、処理後に DeleteMessageCommand でキューから削除します。可視性タイムアウトの概念も含まれています。
// producer.js
import { SQSClient, SendMessageCommand } from "@aws-sdk/client-sqs";
import dotenv from 'dotenv';dotenv.config();
const REGION = process.env.AWS_REGION || "ap-northeast-1";
const SQS_QUEUE_URL = process.env.SQS_QUEUE_URL; // e.g., "https://sqs.ap-northeast-1.amazonaws.com/123456789012/my-test-queue"
if (!SQS_QUEUE_URL) {
console.error("SQS_QUEUE_URL environment variable is not set.");
process.exit(1);
}
const sqsClient = new SQSClient({ region: REGION });
async function sendMessage(messageBody, messageId) {
const params = {
QueueUrl: SQS_QUEUE_URL,
MessageBody: messageBody,
// FIFOキューの場合、MessageGroupIdとMessageDeduplicationIdが必要
// MessageGroupId: "my-message-group",
// MessageDeduplicationId: messageId,
};
try {
const command = new SendMessageCommand(params);
const data = await sqsClient.send(command);
console.log("Producer: Message sent. MessageId:", data.MessageId);
} catch (err) {
console.error("Producer: Error sending message", err);
}
}
async function runProducer() {
console.log("SQS Producer started. Sending messages...");
for (let i = 0; i < 5; i++) {
const message = `Hello SQS from Node.js! Message ${i}`;
await sendMessage(message, `msg-${i}`);
await new Promise(resolve => setTimeout(resolve, 1000)); // 1秒待機
}
console.log("SQS Producer finished sending messages.");
}
runProducer();
// consumer.js
import { SQSClient, ReceiveMessageCommand, DeleteMessageCommand } from "@aws-sdk/client-sqs";
import dotenv from 'dotenv';
dotenv.config();
const REGION = process.env.AWS_REGION || "ap-northeast-1";
const SQS_QUEUE_URL = process.env.SQS_QUEUE_URL;
if (!SQS_QUEUE_URL) {
console.error("SQS_QUEUE_URL environment variable is not set.");
process.exit(1);
}
const sqsClient = new SQSClient({ region: REGION });
async function receiveMessages() {
const params = {
QueueUrl: SQS_QUEUE_URL,
MaxNumberOfMessages: 5, // 一度に最大5メッセージを受信
WaitTimeSeconds: 20, // ロングポーリング (最大20秒)
VisibilityTimeout: 30, // メッセージの可視性タイムアウト (30秒)
};
try {
const command = new ReceiveMessageCommand(params);
const data = await sqsClient.send(command);
if (data.Messages) {