
要約
エンジニアのためのコーディング面接対策 2026: データ構造とアルゴリズム実践ガイド
エンジニアが避けて通れないコーディング面接を攻略し、内定を勝ち取るための実践的なガイドです。
Keywords: コーディング面接, データ構造, アルゴリズム
目次
1. なぜ今、コーディング面接対策が重要なのか?
2. コーディング面接攻略のための基礎固め
3. データ構造の徹底理解と実践
4. アルゴリズムの習得と問題解決アプローチ
5. 実践的な面接対策と効果的な学習戦略
6. よくある落とし穴と回避策
7. FAQ
8. まとめ
背景
1. なぜ今、コーディング面接対策が重要なのか?
2026年、IT業界は常に進化し続け、エンジニアのキャリアパスも多様化しています。しかし、その根幹をなす「コーディング面接」の重要性は、年々増すばかりです。特に、GAFA(Google, Amazon, Facebook/Meta, Apple)や主要なテクノロジー企業では、データ構造とアルゴリズム(DS & Algo)に基づいたコーディング面接が採用プロセスの核となっています。これは単にコードを書く能力を試すだけでなく、論理的思考力、問題解決能力、そしてプレッシャー下でのパフォーマンスを評価するための重要な指標とされているからです。
最近の調査によると、トップティアのテクノロジー企業への応募者の約60%は、コーディング面接の段階で不合格になると言われています。これは、技術力があっても、面接特有のフォーマットやDS & Algoの知識が不足しているために、その能力を十分に発揮できないケースが多いことを示唆しています。特に、未経験からのエンジニア転職や、より高いレベルの企業へのキャリアアップを目指す方にとって、この壁は避けて通れません。
コーディング面接は、あなたのコードがどれだけ効率的か、どれだけ堅牢か、そしてどれだけスケーラブルかを評価します。これは、実務で直面するであろう複雑な問題を解決するための基礎体力を見るものなのです。たとえば、Googleのエンジニアは毎日何十億ものユーザーリクエストを処理するシステムを構築しています。このような環境では、わずかな非効率性がシステム全体に大きな影響を与えるため、データ構造とアルゴリズムの深い理解が不可欠とされます。
ポイント
コーディング面接は、単なるプログラミングスキルのテストではなく、論理的思考力、問題解決能力、そして効率的なコード設計能力を総合的に評価する場です。2026年においても、この傾向は変わらず、むしろその重要性は高まっています。
また、近年はAI技術の進化により、コーディング自体はAIに任せられる部分も増えてきていますが、AIが生成したコードの効率性や最適性を評価し、さらに改善するための「人間の思考力」は依然として重要です。コーディング面接は、まさにその思考力を鍛え、アピールするための絶好の機会と言えるでしょう。このガイドでは、そのための具体的なステップと戦略を詳しく解説していきます。

コアメソッド
2. コーディング面接攻略のための基礎固め
コーディング面接を成功させるためには、まず盤石な基礎を築くことが不可欠です。このセクションでは、データ構造とアルゴリズム学習の全体像と、効果的な学習アプローチについて解説します。
2.1. データ構造とアルゴリズム学習のロードマップ
データ構造とアルゴリズムは広範な分野ですが、コーディング面接に特化して学習する際には、以下のロードマップを参考にすると効率的です。
学習ロードマップの主要フェーズ
フェーズ1: 基本データ構造 — 配列、リンクリスト、スタック、キュー、ハッシュマップなど、最も頻繁に利用されるデータ構造の概念と操作を理解します。
フェーズ2: 基本アルゴリズム — 探索(線形、二分)、ソート(バブル、挿入、選択)といった基礎的なアルゴリズムを学び、時間計算量と空間計算量の概念を把握します。
フェーズ3: 応用データ構造 — ツリー(二分探索木、AVL、赤黒木)、ヒープ、グラフといったより複雑なデータ構造を深く掘り下げます。
フェーズ4: 応用アルゴリズム — 再帰、動的計画法、貪欲法、バックトラッキング、グラフアルゴリズム(DFS, BFS, Dijkstra, Kruskal, Prim)など、難易度の高いアルゴリズムを習得します。
フェーズ5: 問題演習と実践 — LeetCodeなどを用いて、様々な難易度の問題を解き、面接形式でのコミュニケーション練習を重ねます。
このロードマップはあくまで一例であり、ご自身の現在の知識レベルや目標とする企業によって調整が必要です。しかし、どのフェーズにおいても重要なのは、単に暗記するのではなく、「なぜそのデータ構造やアルゴリズムが最適なのか」という根本原理を理解することです。
2.2. 時間計算量と空間計算量(O記法)の理解
コーディング面接において、時間計算量(Time Complexity)と空間計算量(Space Complexity)の分析は非常に重要です。面接官は、あなたの解決策がどれだけ効率的かを評価するために、必ずO記法(Big O Notation)での分析を求めます。
ポイント
O記法は、アルゴリズムの性能をデータ入力サイズ(n)の関数として表現する数学的な表記法です。面接では、最適な解決策だけでなく、その時間的・空間的コストを明確に説明できる能力が求められます。
一般的なO記法の例とその意味を以下に示します。
- O(1) – 定数時間: 入力サイズに関わらず、実行時間が一定。例: 配列の特定インデックスへのアクセス。
- O(log n) – 対数時間: 入力サイズが大きくなると、実行時間は非常にゆっくりと増加。例: 二分探索。
- O(n) – 線形時間: 入力サイズに比例して実行時間が増加。例: 配列の全要素の走査。
- O(n log n) – 線形対数時間: 効率的なソートアルゴリズム(マージソート、クイックソート)でよく見られる。
- O(n^2) – 二次時間: 入力サイズの二乗に比例して実行時間が増加。非効率なソートアルゴリズム(バブルソート)や、ネストされたループ。
- O(2^n) – 指数時間: 入力サイズが少し増えるだけで実行時間が爆発的に増加。再帰的なブルートフォース解法などで見られる。
これらの概念をしっかりと理解し、自分の書いたコードがどのO記法に該当するかを常に意識する練習をしましょう。これは面接での説明能力を向上させるだけでなく、より効率的なコードを書くための思考力を養う上でも不可欠です。
コアメソッド
3. データ構造の徹底理解と実践
データ構造は、情報を効率的に格納し、操作するための「器」です。適切なデータ構造を選択することは、アルゴリズムの効率性を大きく左右します。ここでは、コーディング面接で頻出する主要なデータ構造とその特徴、具体的なユースケースを解説します。
3.1. 配列(Array)
配列は、同じ型のデータを連続したメモリ領域に格納する最も基本的なデータ構造です。インデックスを使って要素に直接アクセスできるため、高速な読み出しが可能です。
配列の基本
特徴 — 要素はインデックスによって順序付けられ、ランダムアクセス(O(1))が可能。
操作 — 要素の追加/削除は、配列の途中の場合はO(n)、末尾の場合は償却O(1)(動的配列の場合)。
ユースケース — 固定サイズのデータ集合、行列演算、一時的なデータバッファ。
コード解説
Pythonにおける配列(リスト)の基本的な操作と、O(1)アクセスおよびO(n)挿入の例を示します。
# Pythonのリストは動的配列として機能します
my_array = [1, 2, 3, 4, 5]
# アクセス (O(1))
print(my_array[2]) # 出力: 3
# 追加 (償却O(1))
my_array.append(6)
print(my_array) # 出力: [1, 2, 3, 4, 5, 6]
# 途中への挿入 (O(n))
my_array.insert(1, 99) # インデックス1に99を挿入
print(my_array) # 出力: [1, 99, 2, 3, 4, 5, 6]
3.2. リンクリスト(Linked List)
リンクリストは、各要素(ノード)が次の要素への参照(ポインタ)を持つデータ構造です。配列と異なり、要素がメモリ上で連続している必要がなく、動的なサイズ変更や要素の挿入/削除が効率的です。
リンクリストの基本
特徴 — 要素がメモリ上で連続しない。動的なサイズ変更が容易。
操作 — 要素の追加/削除はO(1)(ポインタの付け替えのみ)。要素へのアクセスはO(n)(先頭から順にたどる必要がある)。
種類 — 単方向リンクリスト、双方向リンクリスト、循環リンクリスト。
3.3. スタック(Stack)とキュー(Queue)
スタックとキューは、特定のルールに基づいて要素の追加・削除を行う線形データ構造です。
スタック(LIFO – Last In, First Out): 最後に追加された要素が最初に取り出されます。例: Webブラウザの「戻る」ボタンの履歴、関数呼び出しスタック。
キュー(FIFO – First In, First Out): 最初に追加された要素が最初に取り出されます。例: タスクスケジューリング、プリンターの印刷待ち行列。
メリット
✓ データの追加/削除がO(1)で高速。
✓ 特定の処理順序を強制する際にシンプルで効果的。
デメリット
✗ 特定の要素へのランダムアクセスができない(O(n))。
✗ 内部実装によってはサイズ制限がある場合がある。
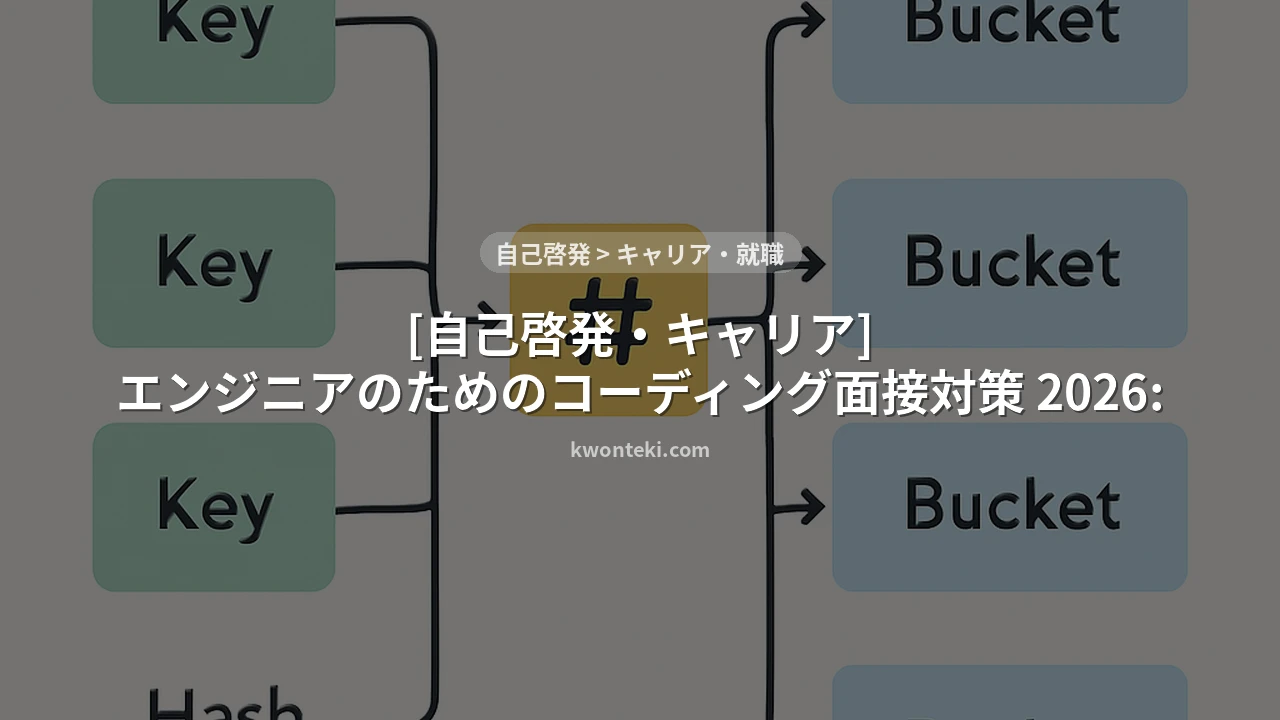
3.4. ハッシュマップ(Hash Map / Dictionary)
ハッシュマップ(Pythonでは辞書、JavaではHashMap)は、キーと値のペアを格納し、キーを使って値を高速に検索できるデータ構造です。内部的にはハッシュ関数を用いてキーをメモリ上のアドレスにマッピングします。
ハッシュマップの強み
特徴 — キーと値のペアでデータを格納。キーによる高速な検索、挿入、削除が可能。
操作 — 平均O(1)で要素の検索、挿入、削除。最悪ケースはO(n)(ハッシュ衝突が多い場合)。
ユースケース — キャッシュ、頻度カウント、重複排除、データベースインデックス。
ハッシュマップは、その高速性からコーディング面接で非常に頻繁に利用されます。例えば、文字列内の各文字の出現頻度を数える問題や、二つの配列の共通要素を見つける問題などで力を発揮します。
3.5. ツリー(Tree)とグラフ(Graph)
ツリーとグラフは、非線形データ構造であり、より複雑な関係性を持つデータを表現するのに使われます。
ツリー: 階層的なデータを表現するのに適しています。根(ルート)から始まり、子ノードへと分岐していきます。最も一般的なのは二分探索木(Binary Search Tree, BST)で、効率的な探索、挿入、削除を可能にします。
グラフ: ノード(頂点)とエッジ(辺)で構成され、ノード間の任意の関係を表現できます。SNSの友人関係、道路網、Webページのリンク構造など、現実世界の多くの問題がグラフとしてモデル化できます。
ポイント
ツリーとグラフは、再帰的な思考や深さ優先探索(DFS)、幅優先探索(BFS)といったアルゴリズムと密接に関連しています。これらのデータ構造を理解することは、複雑な問題解決の鍵となります。
コアメソッド
4. アルゴリズムの習得と問題解決アプローチ
アルゴリズムは、特定の問題を解決するための手順や計算規則の集合です。適切なアルゴリズムを選択し、それを効率的に実装する能力は、コーディング面接で最も重視されるスキルの一つです。ここでは、主要なアルゴリズムとその応用、そして効果的な問題解決アプローチを解説します。
4.1. 探索アルゴリズム
データを効率的に見つけ出すためのアルゴリズムです。主に以下の種類があります。
- 線形探索(Linear Search): 配列の先頭から順に要素を比較していく。O(n)。
- 二分探索(Binary Search): ソートされた配列の中央要素と比較し、探索範囲を半分に絞り込んでいく。O(log n)。非常に高速で、面接で頻出。
- 深さ優先探索(DFS – Depth-First Search): ツリーやグラフにおいて、可能な限り深く探索を進める。再帰やスタックを使って実装。
- 幅優先探索(BFS – Breadth-First Search): ツリーやグラフにおいて、現在のノードから近いノードを順に探索する。キューを使って実装。最短経路問題などで有効。
コード解説
ソート済み配列に対する二分探索のPython実装例です。効率的な探索の基礎となります。
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1 # 見つからなかった場合
sorted_array = [1, 3, 5, 7, 9, 11, 13, 15]
print(binary_search(sorted_array, 7)) # 出力: 3 (インデックス)
print(binary_search(sorted_array, 10)) # 出力: -1
4.2. ソートアルゴリズム
データを特定の順序に並べ替えるアルゴリズムです。効率的なソートは、その後のデータ処理を高速化するため重要です。
- バブルソート、挿入ソート、選択ソート: 比較的シンプルだが効率はO(n^2)。小規模データや教育目的に。
- マージソート(Merge Sort): 分割統治法に基づき、配列を再帰的に分割・結合する。安定ソートで効率はO(n log n)。
- クイックソート(Quick Sort): ピボット要素を基準に分割統治。平均効率はO(n log n)だが、最悪ケースはO(n^2)。インプレースソートが可能。
- ヒープソート(Heap Sort): ヒープデータ構造を利用。効率はO(n log n)。
ポイント
ソートアルゴリズムは、それぞれの特性(安定性、インプレース性、最悪ケースの計算量)を理解し、問題に応じて最適なものを選択することが重要です。
4.3. 動的計画法(Dynamic Programming, DP)
動的計画法は、重複する部分問題を持つ最適化問題を解決するための強力な手法です。問題を小さな部分問題に分割し、その解をメモ化(記憶)して再利用することで、計算量を大幅に削減します。
DPの典型的な問題には、フィボナッチ数列、ナップサック問題、最長共通部分列(LCS)などがあります。DPを習得するには、再帰的な思考と、部分問題の定義、そしてメモ化やテーブル化(ボトムアップ)の実装方法を理解することが鍵となります。
4.4. 貪欲法(Greedy Algorithm)
貪欲法は、各段階でその時点での最適な選択を行うことで、最終的な最適解に到達しようとするアルゴリズムです。常に局所的な最適解を選ぶため、全ての最適化問題に適用できるわけではありませんが、一部の問題(例: コイン交換問題、ハフマン符号化)では非常に効率的です。
4.5. 問題解決アプローチの確立
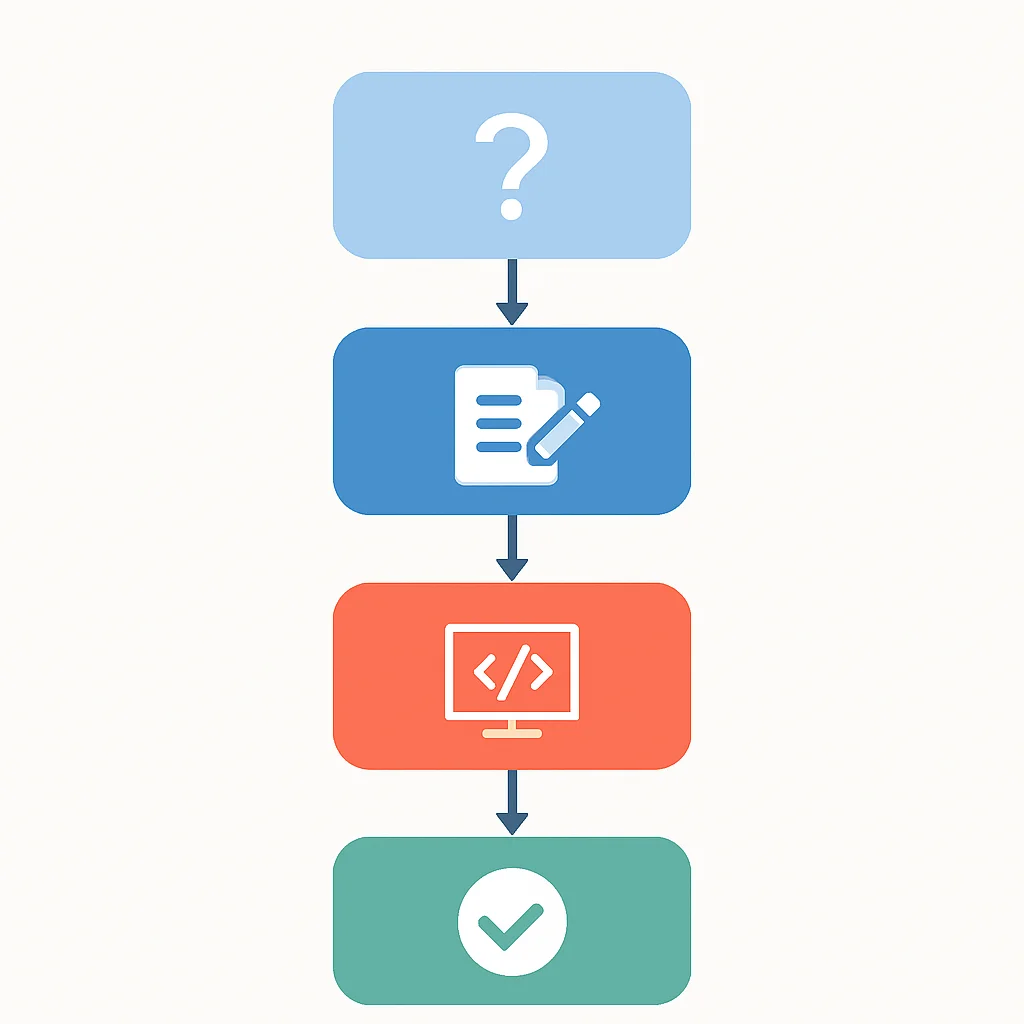
面接では、単に正解を出すだけでなく、どのように問題にアプローチし、解決に至ったかの思考プロセスを説明する能力が重要です。以下のステップを意識して練習しましょう。
1
問題を完全に理解する(Clarify)
例: 入力と出力の形式、制約(数値の範囲、配列のサイズ)、エッジケース(空の入力、単一要素、重複)。不明点は必ず質問し、具体例で確認しましょう。
2
アプローチを計画する(Plan)
例: まずはブルートフォース(力任せ)な解法を考え、時間計算量と空間計算量を分析。その後、データ構造やアルゴリズムを検討して最適化を試みます。複数のアプローチを比較し、なぜそのアプローチを選ぶのかを説明します。
3
コードを実装する(Code)
例: 読みやすく、クリーンなコードを心がけます。変数名や関数名も意味のあるものにしましょう。途中で詰まったら、一旦立ち止まって思考プロセスを共有し、ヒントを求めることも有効です。
4
テストとデバッグ(Test & Debug)
例: 基本的なテストケース、エッジケース(空の入力、最大値、最小値)、不正な入力などを考え、コードが正しく動作するか確認します。バグが見つかった場合は、落ち着いて原因を特定し、修正プロセスを説明しましょう。
実践的応用
5. 実践的な面接対策と効果的な学習戦略
データ構造とアルゴリズムの知識を身につけるだけでは、コーディング面接は突破できません。面接という特殊な状況で、いかに自分の能力を最大限に発揮するかが重要です。ここでは、実践的な面接対策と、2026年の転職・就職活動を成功させるための学習戦略について解説します。
5.1. コミュニケーション能力の重要性
コーディング面接は、単なるプログラミング試験ではありません。面接官は、あなたがチームの一員としてどれだけ効果的にコミュニケーションを取れるかを見ています。具体的には、以下の点が評価されます。
- 問題の明確化: 不明な点を積極的に質問し、問題の要件を正確に理解しようとすること。
- 思考プロセスの言語化: 解法を考える際、なぜそのアプローチを選んだのか、他の選択肢は何か、時間計算量はどうかなどを声に出して説明すること。
- ヒントの活用: 詰まったときに、面接官のヒントを素直に受け入れ、建設的に議論できること。
- エッジケースの検討: コードを書く前に、あるいは書きながら、入力の境界条件や特殊なケースについて言及し、それらをどう処理するかを説明すること。
ポイント
コミュニケーションは、コードの品質と同じくらい重要です。思考を言語化する練習を重ね、面接官を「共同作業者」と見なすことで、より良いパフォーマンスを発揮できます。
5.2. 練習プラットフォームの活用と模擬面接
実践的な演習には、オンラインのプログラミング問題サイトが不可欠です。
- LeetCode: 最も人気があり、難易度別に豊富な問題が用意されています。特に「Top Interview Questions」や「Blind 75/150」リストは、頻出問題の宝庫です。
- AtCoder/TopCoder: 競技プログラミングのプラットフォームですが、アルゴリズムの思考力を鍛えるのに最適です。
- HackerRank: LeetCodeと同様に多くの問題があり、企業別の過去問なども提供されています。
これらのプラットフォームで問題を解く際は、以下の点を意識しましょう。
- タイマーを使う: 実際の面接では時間制限があります(通常30〜45分)。時間を意識して問題を解く練習をしましょう。
- 問題の種類別に練習: 配列、文字列、ツリー、グラフ、DPなど、特定のデータ構造やアルゴリズムに焦点を当てて集中的に練習します。
- 解法を複数考える: 一つの問題に対して、ブルートフォース解法から最適化された解法まで、複数のアプローチを検討する習慣をつけましょう。
- 他者の解法を学ぶ: 自分の解法が最適でなくても、諦めずにディスカッションセクションや公式解法を読んで学習しましょう。
さらに重要なのが「模擬面接」です。友人やメンター、あるいは模擬面接サービスを利用して、実際の面接と同じ環境で練習しましょう。これにより、プレッシャー下でのパフォーマンス、思考の言語化、時間配分などを実践的に改善できます。

5.3. 効果的な学習計画の立て方(2026年版)
2026年のコーディング面接対策として、以下の学習計画を参考にしてください。
チェックリスト
☑ フェーズ1(1ヶ月目):基礎データ構造とアルゴリズム
配列、リンクリスト、スタック、キュー、ハッシュマップ、線形探索、二分探索、簡単なソートアルゴリズムを習得。各10-15問程度を解く。
☑ フェーズ2(2ヶ月目):ツリーとグラフの基礎、DFS/BFS
二分探索木、グラフの表現方法(隣接行列、隣接リスト)、DFS、BFSを習得。各15-20問程度を解く。
☑ フェーズ3(3ヶ月目):応用アルゴリズム(DP、貪欲法、ソート)
動的計画法、貪欲法、マージソート、クイックソート、ヒープソートを習得。DP問題は特に時間をかけて学習。各15-20問程度を解く。
☑ フェーズ4(4ヶ月目〜):総合演習と模擬面接
LeetCodeのMedium/Hardレベルの問題に挑戦。週に1-2回の模擬面接を実施し、フィードバックを基に改善。企業別の過去問にも挑戦。
☐ 継続的な学習と復習
一度解いた問題を定期的に復習し、異なるアプローチを試す。新しいアルゴリズムやデータ構造も常に学習する姿勢を保つ。
この計画は一般的なものであり、個人の進捗に合わせて柔軟に調整してください。重要なのは、毎日少しずつでも継続すること、そしてただ問題を解くだけでなく、なぜその解法が最適なのかを深く考察することです。
問題解決
6. よくある落とし穴と回避策
コーディング面接の準備や本番で、多くの人が陥りがちな「落とし穴」があります。これらを事前に認識し、回避策を講じることで、面接の成功率を格段に高めることができます。
6.1. 問題の要件を完全に理解しないままコーディングを開始する
注意
面接官は、あなたが問題の全ての側面を考慮しているかを見ています。不明瞭な点があるままコードを書き始めると、後で大幅な修正が必要になったり、面接官の意図と異なる解法を提示してしまったりするリスクがあります。
回避策: まずは口頭で質問し、具体例を挙げて要件を明確にしましょう。入力の型、範囲、制約、出力の形式、エッジケース(空の配列、単一要素、負の数、重複など)を徹底的に確認します。ホワイトボードやメモ帳を使って、入力例と期待される出力例を書き出すことも有効です。
6.2. 最適な解法に固執しすぎる
面接では、いきなり最適なO(log n)やO(n)の解法を見つける必要はありません。多くの場合、まずはブルートフォース(O(n^2)など)の解法を提示し、その後に段階的に最適化していくプロセスが評価されます。
ポイント
まずは「動くコード」を書き、次に「より良いコード」を目指すというステップを踏みましょう。面接官はあなたの思考過程を見たがっています。
回避策: まずはシンプルで分かりやすい(ただし非効率でも良い)解法を説明し、その時間・空間計算量を分析します。その後、「この解法を改善するにはどうすればよいか?」と自問自答し、面接官と議論しながらより効率的なデータ構造やアルゴリズムを検討しましょう。
6.3. コードの読みやすさやテストを軽視する
実務では、コードの可読性や保守性が非常に重要です。面接でも同様に、読みやすいコード、適切な変数名、コメント、そしてテストケースへの配慮が評価されます。
注意
動かない、あるいは読みにくいコードは、あなたの能力を正確に伝えることができません。面接官は、あなたが書いたコードを理解し、レビューする立場にあります。
回避策: コードを書く際は、意味のある変数名と関数名を使い、必要に応じて短いコメントを追加しましょう。コードを書き終えたら、必ず自分でテストケースをいくつか考え、頭の中でコードの実行をシミュレーション(ウォークスルー)してください。特にエッジケースでの動作を確認することが重要です。

6.4. 練習不足によるパフォーマンスの低下
知識があっても、それを制限時間内にアウトプットする練習が不足していると、本番で実力を発揮できません。特に、ホワイトボードコーディングやオンラインエディタでのコーディングに慣れていないと、思考が止まってしまうことがあります。
回避策: 定期的に時間を計って問題を解く練習をしましょう。LeetCodeやHackerRankなどのプラットフォームを積極的に活用し、異なる種類の問題に触れてください。また、模擬面接を繰り返し行うことで、本番の緊張感に慣れることができます。面接の数週間前からは、毎日最低1問は解くなど、集中して取り組む期間を設けることをお勧めします。
よくある質問(FAQ)
Q. コーディング面接対策はどれくらいの期間が必要ですか?
個人の現在のスキルレベルによりますが、基礎から始めてトップ企業を目指す場合、一般的には3ヶ月から6ヶ月の集中的な学習期間が必要です。週に15〜20時間程度の学習時間を確保できると理想的です。
Q. どのプログラミング言語で練習すべきですか?
Python、Java、C++が最も一般的です。Pythonは記述が簡潔で、アルゴリズムの思考に集中しやすいため、初心者にもおすすめです。JavaやC++は、より低レベルなメモリ管理やパフォーマンスを問われる場合に有利です。自分が最も慣れている言語を選ぶのが一番ですが、Pythonは面接で非常に広く受け入れられています。
Q. 面接で最適な解法が見つからなかった場合どうすればよいですか?
まずは、思いつく限りの解法(ブルートフォースでも可)を面接官に説明し、その時間・空間計算量を分析しましょう。その後、「この解法を改善するために、他にどのようなデータ構造やアルゴリズムが考えられますか?」と積極的に面接官に相談し、ヒントを求める姿勢が重要です。思考プロセスを共有することが評価されます。
Q. 競技プログラミングの経験はコーディング面接に役立ちますか?
はい、非常に役立ちます。競技プログラミングは、限られた時間内で複雑な問題を素早く分析し、効率的なアルゴリズムを設計・実装する能力を鍛えるのに最適です。ただし、競技プログラミングの問題は面接問題よりも数学的・理論的な側面が強いこともあるため、面接対策に特化した問題演習も並行して行うと良いでしょう。
まとめ
7. まとめ
本記事では、2026年のエンジニア向けコーディング面接を攻略するための実践的なガイドとして、データ構造とアルゴリズムの基礎から、問題解決アプローチ、効果的な学習戦略、そしてよくある落とし穴とその回避策について詳しく解説しました。
コーディング面接は、単なる技術力のテストではなく、あなたの論理的思考力、問題解決能力、そしてコミュニケーション能力を総合的に評価する場です。そのため、単にコードを書けるだけでなく、なぜそのコードを書いたのか、どのような思考プロセスを経てその解法に至ったのかを明確に説明できる能力が求められます。
ポイント
コーディング面接の成功は、適切な知識、効果的な練習、そして自信を持って思考を共有する能力の組み合わせにかかっています。焦らず、着実にステップを踏んで準備を進めましょう。
データ構造とアルゴリズムの学習は、一朝一夕で身につくものではありません。しかし、地道な努力と継続的な実践を重ねることで、必ず成果は現れます。LeetCodeなどのプラットフォームを活用し、時間を計って問題を解く練習を繰り返し、模擬面接で実践力を高めてください。そして、常に「なぜ?」という問いを忘れず、深い理解を目指しましょう。
Kwontekiは、あなたのキャリアアップを全力で応援します。このガイドが、あなたの2026年の転職・就職活動において、内定を勝ち取るための一助となれば幸いです。自信を持って、次なる挑戦に臨んでください!
最後までお読みいただきありがとうございます!
Kwontekiでは、エンジニアのキャリア形成に役立つ情報や自己啓発コンテンツを定期的に発信しています。今回の記事があなたのコーディング面接対策に少しでも貢献できたなら幸いです。
ご質問やフィードバックがあればコメントでお知らせください!