

要約
2026年半導体技術最前線: 開発者が知るべき次世代チップの進化と影響
2026年の半導体業界を牽引する最新プロセス技術(例: 2nm)とチップレット戦略を解説し、AI、クラウド、モバイル開発に与える影響を深掘りします。
Keywords: 半導体, プロセス技術, チップレット
目次
1. はじめに:半導体進化の重要性と2026年の展望
2. プロセス技術の最前線:2nmノードがもたらす革新
3. チップレット戦略:複雑性を乗り越える設計革命
4. AIチップの進化と専門化:次世代AIの推進力
5. 開発者への影響:クラウド、モバイル、エッジコンピューティングの変革
6. 技術的課題と解決策:高性能化の壁を乗り越える
7. よくある質問 (FAQ)
8. まとめ:半導体技術の未来と開発者の役割
1. はじめに:半導体進化の重要性と2026年の展望
テクノロジーの進化は、半導体チップの性能向上と密接に結びついています。スマートフォンからデータセンター、そして最新のAIモデルに至るまで、その基盤を支えるのはすべて半導体です。2026年、私たちは半導体技術の新たなマイルストーンを迎えようとしています。ムーアの法則が物理的な限界に近づく中で、業界は単なる微細化を超えた革新的なアプローチを模索し、実現しつつあります。
本記事では、2026年に焦点が当たる次世代半導体技術、特に「2nmプロセス」と「チップレット戦略」に焦点を当て、それらがAI、クラウド、モバイルといった主要なテクノロジー分野にどのような影響を与えるのかを、開発者の視点から深く掘り下げていきます。これらの技術トレンドを理解することは、未来のアプリケーション開発やシステム設計において、競争優位性を確立するために不可欠です。
半導体技術の進化は、単に計算速度が上がるという話に留まりません。それは、より複雑なAIモデルをリアルタイムで実行する能力、モバイルデバイスのバッテリー持続時間の劇的な延長、そしてデータセンターの電力効率の大幅な改善といった、私たちのデジタルライフ全体を根底から変える可能性を秘めています。この技術革新の波を捉え、自身の開発にどう活かすべきか、具体的な視点を提供することを目指します。
ポイント
2026年の半導体技術は、2nmプロセスとチップレット戦略を中心に進化し、AI、クラウド、モバイル開発に革命的な影響を与えます。この進化を理解し、活用することが開発者にとって重要です。
2. プロセス技術の最前線:2nmノードがもたらす革新
半導体製造プロセスにおける「2nm」という数字は、トランジスタのゲート長や物理的なサイズを直接示すものではなく、技術世代を示すマーケティング上の名称です。しかし、この2nmノードへの移行は、集積度、性能、電力効率においてこれまでの世代を大きく上回る革新をもたらすと期待されています。
2.1. 2nmプロセスの核心技術:GAAFETとEUVリソグラフィ
2nmプロセスにおける最大の技術的転換点は、従来のFinFET構造から「GAAFET(Gate-All-Around FET)」、具体的にはTSMCやSamsungが採用する「MBCFET(Multi-Bridge-Channel FET)」への移行です。FinFETではゲートがチャネルの3面を囲んでいましたが、GAAFETではゲートがチャネルの全周を囲むことで、より優れたゲート制御性を実現します。これにより、リーク電流を劇的に削減し、トランジスタのスイッチング性能と電力効率を向上させることが可能になります。
この微細な構造を形成するためには、極端紫外線(EUV)リソグラフィ技術が不可欠です。EUVは、従来の光リソグラフィよりもはるかに短い波長(13.5nm)の光を使用することで、より微細なパターンをシリコンウェハ上に転写できます。2nmプロセスでは、EUVの多層パターニングや高NA(開口数)EUVの導入がさらに進み、製造の複雑性とコストが増大する一方で、その精密さが次世代チップの実現を可能にします。
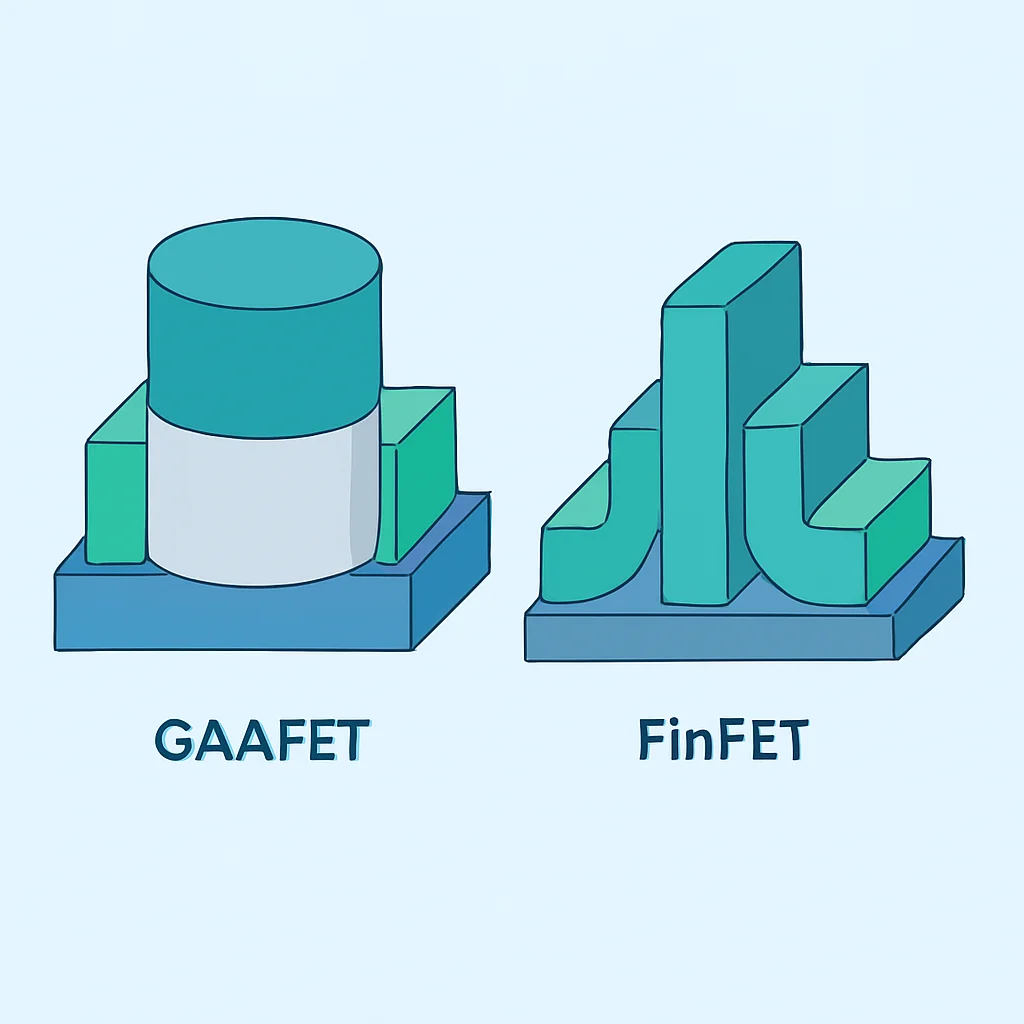
2.2. 主要ファウンドリの動向と性能予測
2026年に向けて、主要な半導体ファウンドリは2nmプロセスの量産化を競い合っています。TSMCは「N2」プロセスとして2025年後半から2026年にかけて量産を開始すると見られており、Samsungも「SF2」として同時期での量産を目指しています。Intelは「Intel 20A」として2024年後半の導入を計画しており、これは実質的に2nmクラスの技術に相当します。各社が独自のアプローチでGAAFET(IntelはRibbonFETと呼称)とEUV技術を駆使し、性能と電力効率の限界を押し広げようとしています。
一般的に、2nmプロセスは、前世代の3nmプロセスと比較して、同等の消費電力で約10〜15%の性能向上、または同等の性能で約25〜30%の消費電力削減を実現すると予測されています。また、トランジスタ密度も大幅に向上し、チップ面積の縮小や、より多くの機能を搭載することが可能になります。例えば、AIアクセラレータでは、コア数を増やしつつ消費電力を抑えることで、テラオペレーション/秒(TOPS)あたりの効率が向上し、データセンターの総所有コスト(TCO)削減に貢献します。
ポイント
2nmプロセスはGAAFET(MBCFET/RibbonFET)とEUVリソグラフィによって実現され、性能、電力効率、集積度を大幅に向上させます。TSMC、Samsung、Intelが2026年前後に量産を予定しており、AIチップやモバイルプロセッサの性能を飛躍的に高めるでしょう。
プロセスノード進化の比較 (2026年時点)
主要ファウンドリの次世代プロセス技術の概要
| ファウンドリ | プロセス名 | トランジスタ構造 | 量産時期 (予測) | 主な利点 |
|---|---|---|---|---|
| TSMC | N2 | GAAFET (MBCFET) | 2025年後半〜2026年 | 高性能、低消費電力 |
| Samsung | SF2 | GAAFET (MBCFET) | 2025年後半〜2026年 | 電力効率、面積削減 |
| Intel | Intel 20A | GAAFET (RibbonFET) | 2024年後半 | 高性能、Backside Power Delivery (PowerVia) |
3. チップレット戦略:複雑性を乗り越える設計革命
半導体の微細化が進むにつれて、単一の巨大なモノリシック(一枚岩)チップを製造するコストとリスクが増大しています。特に、歩留まりの低下は製造コストに直結し、設計の柔軟性も制限されます。この課題を解決するために、2026年には「チップレット戦略」が半導体設計の主流となると予測されています。
3.1. チップレットとは何か、そのメリット
チップレットとは、複数の小さな半導体ダイ(チップレット)を一つのパッケージ上で統合し、あたかも一つの大きなチップであるかのように機能させる技術です。これにより、以下のような多大なメリットが生まれます。
歩留まりの向上とコスト削減: 小さなダイは欠陥の影響を受けにくく、製造歩留まりが高くなります。不良品が出た場合でも、特定のチップレットだけを交換すれば良いため、全体のコストを抑えることができます。例えば、モノリシックな巨大GPUの歩留まりが50%だった場合、それを4つのチップレットに分割し、それぞれの歩留まりが90%であれば、全体の歩留まりは0.9^4 = 約65%に向上します。
設計の柔軟性とカスタマイズ性: 異なるプロセスノードで製造されたチップレットを組み合わせることが可能です。例えば、高性能なCPUコアは最先端の2nmプロセスで、I/Oコントローラやメモリコントローラは成熟したプロセス(例: 7nmや12nm)で製造し、それらを統合することで、コストと性能のバランスを最適化できます。これにより、特定のアプリケーションに特化したカスタムチップをより迅速かつ効率的に開発できるようになります。
異種統合(Heterogeneous Integration): CPU、GPU、NPU、HBM(高帯域幅メモリ)など、異なる機能を持つチップレットを密接に統合することで、単一チップでは実現困難な高性能・高効率なシステムを構築できます。これは特にAIアクセラレータやデータセンター向けプロセッサにおいて、極めて重要な技術となります。

3.2. チップレット間の接続技術:UCIeの重要性
チップレット戦略を成功させる上で不可欠なのが、チップレット間の高速かつ効率的な接続技術です。これまで各社が独自のインターコネクト技術(例: AMDのInfinity Fabric、IntelのEMIB/Foveros)を開発してきましたが、2026年には「UCIe(Universal Chiplet Interconnect Express)」のような業界標準規格の普及が加速すると見られています。
UCIeは、チップレット間の物理層、リンク層、トランザクション層を定義し、異なるベンダーが製造したチップレット同士でも相互接続を可能にすることを目指しています。これにより、チップレットのエコシステムが拡大し、より多様な部品を組み合わせて革新的な製品を開発できるようになります。データ転送速度は、オンパッケージ接続で最大数TB/sに達し、低消費電力で超高帯域幅を実現します。
コード解説
UCIeを介したチップレット間の通信を抽象的に表現した設定ファイルのスニペットです。実際のハードウェア設定は複雑ですが、概念的にはこのような形で異なるチップレットが互いのリソースを認識し、連携するイメージです。
<!-- Hypothetical UCIe configuration for a multi-chiplet system -->
<chiplet_system name="NextGenAIProcessor">
<chiplet id="CPU_Core_Complex" type="CPU" process="N2" vendor="VendorA">
<interface type="UCIe" target="AI_Accelerator_0" bandwidth="2TB/s"/>
<interface type="UCIe" target="Memory_Controller" bandwidth="1TB/s"/>
</chiplet>
<chiplet id="AI_Accelerator_0" type="NPU" process="N3" vendor="VendorB">
<interface type="UCIe" target="CPU_Core_Complex" bandwidth="2TB/s"/>
<interface type="UCIe" target="Memory_Controller" bandwidth="1TB/s"/>
<memory type="HBM3" capacity="64GB"/>
</chiplet>
<chiplet id="Memory_Controller" type="MemoryIO" process="N7" vendor="VendorC">
<interface type="UCIe" target="CPU_Core_Complex" bandwidth="1TB/s"/>
<interface type="UCIe" target="AI_Accelerator_0" bandwidth="1TB/s"/>
<external_memory type="DDR5" slots="4"/>
</chiplet>
</chiplet_system>
ポイント
チップレット戦略は、歩留まり向上、コスト削減、設計の柔軟性、そして異種統合を実現する上で不可欠です。UCIeのような標準化されたインターコネクト技術が普及することで、半導体エコシステムはさらに活性化し、カスタムチップ開発が加速します。
4. AIチップの進化と専門化:次世代AIの推進力
AI技術の爆発的な発展、特に生成AIモデルの登場は、かつてないほどの計算能力を要求しています。2026年、半導体業界は、このAIの需要に応えるべく、より高性能で電力効率の高いAIチップの開発に注力しており、その進化は多岐にわたります。
4.1. GPUからASIC、NPUへ:AIアクセラレータの多様化
初期のAI開発では、汎用性の高いGPUがその並列計算能力から主流でした。しかし、特定のAIワークロードに最適化された専用ハードウェアの需要が高まり、ASIC(Application-Specific Integrated Circuit)やNPU(Neural Processing Unit)の重要性が増しています。
GPUの進化: NVIDIAのHopperやBlackwellアーキテクチャのように、GPUは引き続きAIトレーニングと推論の両方で重要な役割を果たします。2nmプロセスとチップレット技術の恩恵を受け、HBM(High Bandwidth Memory)の容量と帯域幅がさらに向上し、Transformerモデルのような大規模モデルの処理能力が飛躍的に高まります。例えば、次世代HBM3Eは、ピンあたり9.2Gbps以上の速度で、単一スタックで最大36GBの容量、1.2TB/sの帯域幅を提供すると予測されています。
ASICの台頭: GoogleのTPU、AWSのTrainium/Inferentia、MicrosoftのAthenaなど、クラウドプロバイダーは自社データセンター向けにカスタムASICを開発しています。これらのチップは、特定のAIモデル(例: Transformer、CNN)の計算パターンに特化することで、GPUよりも高い電力効率とコスト効率を実現します。2026年には、これらのASICがさらに進化し、特に推論ワークロードにおいて高いコストパフォーマンスを発揮するでしょう。
NPUの普及: スマートフォンやエッジデバイスでは、電力制約の中でAI処理を行うためにNPUが不可欠です。QualcommのSnapdragon、AppleのNeural Engine、MediaTekのAPUなどがその例です。2nmプロセスにより、これらのNPUはより多くのAIコアを搭載し、オンデバイスでの複雑な画像認識、音声処理、自然言語処理をリアルタイムかつ低消費電力で実行できるようになります。これにより、個人情報保護の観点からも、クラウドにデータを送らずにデバイス内でAI処理を完結させる「エッジAI」の適用範囲が拡大します。
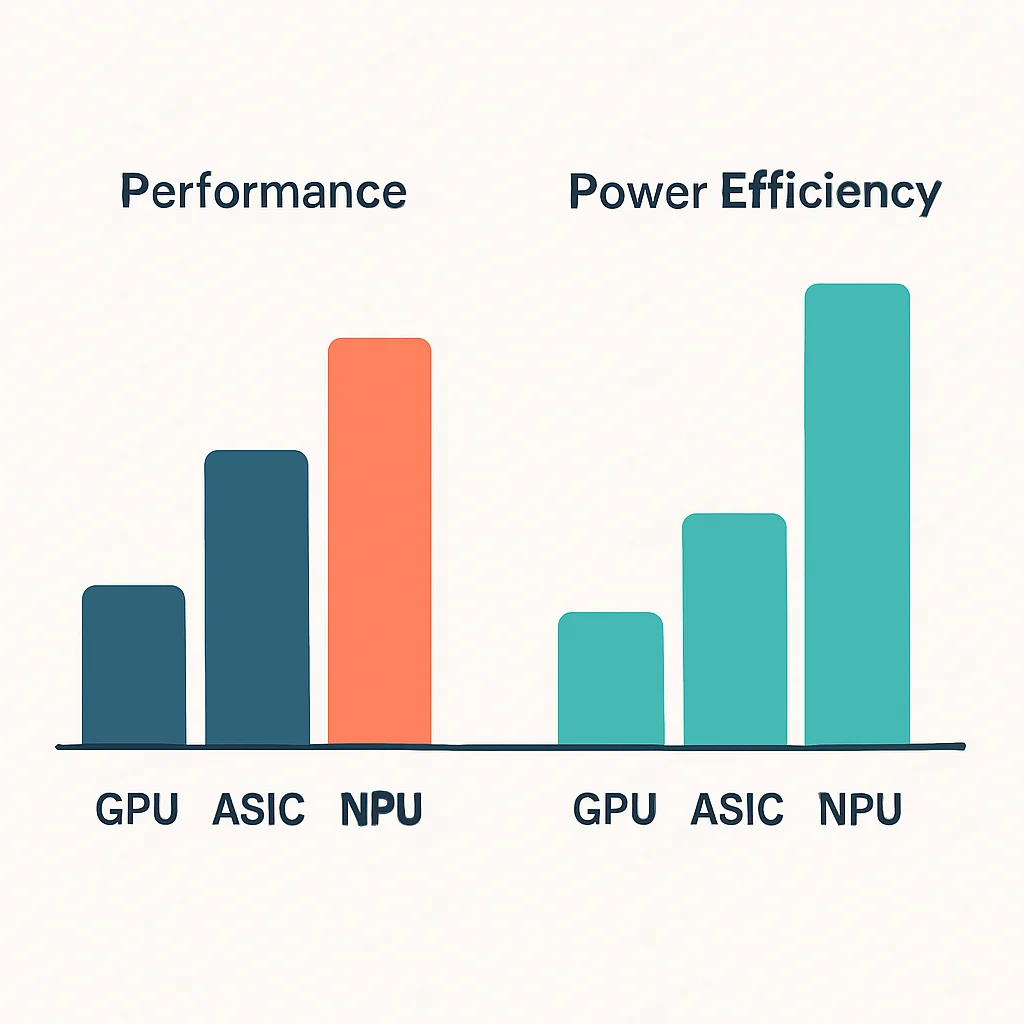
4.2. HBMとメモリの重要性
AIチップの性能は、計算能力だけでなく、メモリ帯域幅によっても大きく左右されます。特に大規模なAIモデルでは、膨大な量のデータを頻繁にメモリから読み書きする必要があるため、HBM(高帯域幅メモリ)の採用が不可欠です。HBMは、DRAMダイを垂直に積層し、プロセッサと超広帯域のインターポーザーを介して接続することで、従来のDDRメモリと比較して桁違いの帯域幅を実現します。
2026年には、HBM3E(Enhanced)やその次世代規格が普及し、AIチップのメモリボトルネックがさらに緩和されます。例えば、HBM3Eは最大8層スタックで、1スタックあたり最大24GB〜36GBの容量を持ち、合計で最大1.2TB/s以上の帯域幅を提供します。これにより、数千億から兆単位のパラメータを持つ生成AIモデルのトレーニング時間を短縮し、より大規模なデータセットでの学習を可能にします。また、推論においても、より複雑なモデルを低遅延で実行できるようになります。
メリット
✓ 高性能化: 2nmプロセスとHBMの組み合わせで、AIモデルのトレーニングと推論速度が大幅に向上。
✓ 電力効率: GAAFET構造とASIC/NPUの最適化により、消費電力を抑えつつ高いAI性能を実現。
✓ エッジAIの強化: モバイルデバイスでの複雑なAI処理が可能になり、プライバシー保護とリアルタイム応答性が向上。
デメリット
✗ 開発コスト増大: 最先端プロセスやHBMの採用はチップ設計・製造コストを押し上げる。
✗ 供給網のリスク: 特定ファウンドリへの依存度が高まり、地政学的リスクや供給制約が影響する可能性。
✗ 冷却課題: 高性能チップは発熱量も大きくなるため、効果的な冷却ソリューションが不可欠。
ポイント
2026年のAIチップは、GPU、ASIC、NPUの多様化と専門化が進み、HBMのような高帯域幅メモリとの統合がさらに強化されます。これにより、生成AIからエッジAIまで、あらゆるAIアプリケーションの性能と効率が飛躍的に向上します。
5. 開発者への影響:クラウド、モバイル、エッジコンピューティングの変革
半導体技術の進化は、開発者がアプリケーションを設計し、デプロイする方法に直接的な影響を与えます。特にクラウドコンピューティング、モバイル、エッジコンピューティングの各分野では、その影響は顕著です。
5.1. クラウドコンピューティング:カスタムシリコンと最適化
データセンターでは、2nmプロセスで製造されたCPUやGPU、そしてチップレットベースのカスタムAIアクセラレータが普及します。これにより、クラウドプロバイダーはより高い計算密度と電力効率を実現し、ユーザーはより高速かつ低コストでサービスを利用できるようになります。
開発者は、これらの新しいハードウェアの特性を最大限に活用するために、以下のような点に注目する必要があります。
・ワークロードの最適化: どのAIモデルをどのアクセラレータ(GPU、TPU、Inferentiaなど)で実行するのが最も効率的かを見極める必要性が高まります。TensorFlowやPyTorchのようなフレームワークは、異なるハードウェアバックエンドに対応するための最適化オプションを提供し続けるでしょう。
・コンテナ化とオーケストレーション: 異種ハードウェア環境でアプリケーションを効率的にデプロイ・管理するために、Kubernetesなどのコンテナオーケストレーションツールがさらに進化します。特定のアクセラレータにワークロードを割り当てるスケジューリング機能が強化されます。
・データ転送の最適化: 高速な処理能力に見合うデータ転送速度が求められます。NVMe over Fabrics (NVMe-oF) やCXL (Compute Express Link) のような技術が、CPUとメモリ、アクセラレータ間のデータボトルネックを解消するために重要になります。
ユースケース:生成AIサービスのスケール
2nmプロセスの次世代AIアクセラレータとHBM3Eを搭載したクラウドインスタンスを利用し、数千億パラメータを持つ大規模言語モデル(LLM)の推論をリアルタイムで実行。ユーザーからの問い合わせに対して、低遅延で高精度な回答を生成するチャットボットサービスを大規模展開。

5.2. モバイルデバイス:オンデバイスAIと没入型体験
2nmプロセスで製造されたモバイルプロセッサは、スマートフォンやタブレットの性能を劇的に向上させます。特に、強化されたNPUは、オンデバイスAIの能力を飛躍的に高めます。これにより、開発者は以下のような新しいアプリケーションや機能を提供できるようになります。
・高度な画像・動画処理: デバイス内でのリアルタイム4K動画編集、プロフェッショナルレベルの画像補正、AIを活用した写真の自動分類や検索などが、より高速かつ電力効率よく行えるようになります。
・自然言語処理と音声アシスタント: クラウドへの依存を減らし、デバイス内でより複雑な音声コマンド認識や自然言語理解が可能です。これにより、オフラインでのAIアシスタント利用や、プライバシーに配慮した個人情報処理が普及します。
・XR(AR/VR)体験の強化: モバイルデバイス上での高精細なAR/VRコンテンツのレンダリングや、リアルタイムの空間認識、ジェスチャー認識などが可能になり、没入感のある体験を提供します。モバイルプロセッサのグラフィック性能とAI性能が、次世代のウェアラブルデバイスやヘッドセットの普及を後押しします。
ユースケース:リアルタイムAR翻訳アプリ
スマートフォンのカメラで捉えたテキストを、強化されたNPUがデバイス内でリアルタイムに認識・翻訳し、ARオーバーレイとして表示。海外旅行中に看板やメニューを瞬時に翻訳し、ユーザー体験を向上させる。
5.3. エッジコンピューティング:低遅延と自律性
IoTデバイスや産業用システム、自動運転車などのエッジデバイスでは、クラウドへのデータ転送に伴う遅延や帯域幅の制約が課題となります。次世代半導体は、エッジデバイスがより多くのAI処理をローカルで実行することを可能にし、低遅延で自律的な運用を実現します。
・リアルタイム応答性: 工場のロボットアームがカメラで捉えた画像を瞬時に分析し、異常を検知して停止する、自動運転車が周囲の状況をリアルタイムで判断して安全な走行経路を選択するなど、ミリ秒単位の応答が求められるアプリケーションでの適用が拡大します。
・データプライバシーとセキュリティ: 機密性の高いデータ(医療データ、個人監視データなど)をクラウドに送信することなく、デバイス内で処理・分析することで、プライバシー保護とセキュリティを強化できます。
・ネットワーク負荷の軽減: 全てのデータをクラウドに送信するのではなく、エッジで前処理やフィルタリングを行うことで、ネットワーク帯域幅の消費を抑え、クラウドインフラのコスト削減にも貢献します。
ユースケース:スマートシティの交通最適化
交差点に設置されたエッジAIカメラが、次世代半導体を搭載したNPUで車両や歩行者の動きをリアルタイム分析。信号機を最適に制御し、交通渋滞を緩和するとともに、緊急車両の優先通行を自動で確保する。
ポイント
2026年の半導体進化は、クラウドではカスタムシリコンによる効率化、モバイルではオンデバイスAIによる没入型体験、エッジでは低遅延と自律性を実現し、開発者に新たな可能性と最適化の機会を提供します。
6. 技術的課題と解決策:高性能化の壁を乗り越える
半導体技術が2nmノードやチップレットへと進化する一方で、それに伴う新たな技術的課題も浮上しています。これらの課題を克服するための研究開発が、2026年以降のさらなる進化を左右します。
6.1. 製造歩留まりとコストの増大
問題 01
極端な微細化による製造歩留まりの低下とコストの急増
2nmプロセスのような最先端ノードでは、EUVリソグラフィの多層化やGAAFET構造の複雑化により、わずかな欠陥でもチップ全体が不良品となるリスクが高まります。これにより製造歩留まりが低下し、1枚のウェハから得られる良品チップの数が減るため、チップあたりの製造コストが急騰します。EUV装置自体の価格も非常に高価であり、研究開発費も膨大です。
解決策
チップレット戦略の推進: 巨大なモノリシックチップを小さなチップレットに分割することで、個々のチップレットの歩留まりを向上させ、全体としての良品率を高めます。不良品が出た場合でも、特定のチップレットのみを廃棄・交換すれば良いため、コストを効率的に管理できます。
AIを活用した欠陥検出: 製造プロセス中に発生する微細な欠陥をAIベースの画像認識技術で早期に検出し、製造プロセスの最適化を加速します。これにより、歩留まり向上サイクルを短縮し、コスト削減に貢献します。
材料科学の革新: 新しい材料(例: 2D材料、新しいゲート誘電体)の研究開発を進め、トランジスタ性能を向上させつつ、製造の複雑性を緩和するアプローチも模索されています。
6.2. 発熱と電力供給の課題
問題 02
高集積化による発熱量の増大と安定した電力供給の困難さ
トランジスタの集積度が向上すると、単位面積あたりの消費電力と発熱量が飛躍的に増大します。これにより、チップの信頼性低下や性能劣化(熱暴走)、さらにはデータセンター全体の冷却コスト増大を招きます。また、微細化されたトランジスタに安定した電力を供給することも、電圧降下やノイズの問題から非常に困難になります。
解決策
Backside Power Delivery (BPD) の導入: IntelのPowerViaのように、電力供給ネットワークをトランジスタ層の裏側に配置することで、信号配線と電力配線を分離し、電力供給の効率と安定性を向上させます。これにより、電圧降下を低減し、信号ノイズを抑制します。
先進的な冷却技術: 液冷、浸漬冷却、マイクロ流体冷却などの先進的な冷却技術が、データセンターや高性能コンピューティング(HPC)環境でさらに普及します。チップパッケージレベルでの熱伝導率の高い材料や、3D積層チップ内のマイクロチャネル冷却も研究されています。
電力管理の最適化: 動的な電圧・周波数スケーリング(DVFS)や、AIを活用したワークロードベースの電力最適化アルゴリズムが、チップレベルで消費電力を効率的に管理し、発熱を抑制します。
6.3. チップレット間のデータ転送ボトルネック
問題 03
複数のチップレット間の超高速データ転送におけるボトルネック
チップレットが普及するにつれて、異なるチップレット間で大量のデータを効率的かつ低遅延でやり取りすることが重要な課題となります。インターコネクトの帯域幅が不足したり、遅延が大きかったりすると、チップレット統合のメリットが半減し、全体的なシステム性能が低下します。特に、AIワークロードではHBMとプロセッサ間のデータ移動が頻繁に発生するため、このボトルネックは深刻です。
解決策
UCIeおよびCXLの普及: UCIeのような標準化されたチップレット間インターフェースは、高帯域幅と低遅延を提供します。また、CXL(Compute Express Link)は、CPUとアクセラレータ、メモリ間でキャッシュコヒーレンシを維持しつつ、高速なデータ共有を可能にする技術であり、データ転送ボトルネックの解消に貢献します。
先進パッケージング技術: 2.5D/3Dパッケージング技術(例: TSMCのCoWoS、IntelのFoveros)は、チップレットを密接に統合し、超短距離で超高帯域幅の接続を実現します。シリコンインターポーザーやブリッジ技術を用いることで、チップレット間の配線長を最小限に抑え、電気信号の遅延と消費電力を削減します。
オンパッケージメモリの最適化: HBMなどの高帯域幅メモリをプロセッサチップレットと同じパッケージに統合することで、メモリとプロセッサ間の物理的な距離を最小化し、データ転送ボトルネックを大幅に軽減します。
ポイント
2nmプロセスやチップレット技術の導入に伴う課題は、製造歩留まり、発熱・電力供給、データ転送ボトルネックに集約されます。これらは、チップレット戦略、BPD、先進冷却、UCIe/CXL、先進パッケージングなどの複合的な技術革新によって解決が進められています。
よくある質問 (FAQ)
Q. 2nmプロセスとは具体的に何ですか?
A. 2nmプロセスは、トランジスタの物理的なサイズを直接示すものではなく、半導体製造技術の世代を表すマーケティング上の名称です。この世代では、GAAFET(Gate-All-Around FET)と呼ばれる新しいトランジスタ構造と、極端紫外線(EUV)リソグラフィ技術が採用され、大幅な性能向上と電力効率の改善が期待されています。
Q. チップレット戦略の最大のメリットは何ですか?
A. チップレット戦略の最大のメリットは、製造歩留まりの向上と設計の柔軟性です。巨大なチップを小さなブロックに分割することで、製造時の欠陥リスクを低減し、コストを抑えられます。また、異なるプロセスノードやベンダーのチップレットを組み合わせて、特定の用途に最適化されたカスタムチップを効率的に開発できるようになります。
Q. AIチップの進化は開発者にどのような影響を与えますか?
A. AIチップの進化は、開発者がより高性能で電力効率の良いAIアプリケーションを構築する機会を提供します。クラウドでは大規模AIモデルの高速処理、モバイルではオンデバイスAIによるプライバシー保護とリアルタイム応答、エッジでは低遅延で自律的なAI機能の実装が可能になり、新たなサービスやユーザー体験の創出が期待されます。
Q. 半導体技術の進化に伴う主な課題は何ですか?
A. 主な課題は、製造歩留まりの低下とコストの急増、高集積化による発熱量の増大と安定した電力供給の困難さ、そしてチップレット間の超高速データ転送におけるボトルネックです。これらはチップレット戦略、Backside Power Delivery (BPD)、先進冷却技術、UCIe/CXLなどの技術革新によって解決が進められています。
Q. 2026年以降、半導体市場で特に注目すべきトレンドは何ですか?
A. 2026年以降も、2nm以下のプロセスノードへの微細化競争、チップレット技術のさらなる標準化と普及、AIに特化したカスタムシリコンの多様化、そして先進パッケージング技術の進化が主要なトレンドとして注目されます。これらは、AI、HPC、自動運転、メタバースなど、未来のテクノロジーを支える基盤となります。
7. まとめ:半導体技術の未来と開発者の役割
2026年、半導体技術はかつてない変革期を迎えています。2nmプロセスによるトランジスタ性能の限界突破、そしてチップレット戦略による設計の柔軟性とコスト効率の向上は、AI、クラウド、モバイル、エッジコンピューティングといったあらゆるテクノロジー領域に深く、広範な影響を及ぼします。
開発者の皆さんにとって、この進化は単なるハードウェアのスペック向上以上の意味を持ちます。それは、より複雑で高性能なAIモデルを効率的に実行し、リアルタイムでユーザーにインテリジェントな体験を提供し、さらにはデバイスのプライバシーとセキュリティを強化するための新たなツールと機会を意味します。新しいプロセッサアーキテクチャや異種統合されたチップレットに対応するためのソフトウェア最適化、そして適切なハードウェアプラットフォームを選択する知識が、これまで以上に重要になります。
Kwontekiでは、これからも半導体技術の最前線を追いかけ、開発者の皆さんがその恩恵を最大限に活用できるような情報を提供していきます。この急速な進化の波に乗り、未来のテクノロジーを共に創造していきましょう。
ポイント
2026年の半導体技術進化は、開発者に新たな可能性と最適化の機会をもたらします。ハードウェアの進化を理解し、ソフトウェアの最適化を通じて、未来のアプリケーションとサービスを創造する役割が期待されています。
最後までお読みいただきありがとうございます
2026年の半導体技術の進化は、私たちのデジタル世界をさらに豊かにするでしょう。Kwontekiでは、これからも最新のテックトレンドを分かりやすく解説していきます。
ご質問があればコメントでどうぞ。