

要約
クラウドネイティブ監視入門 2026: PrometheusとGrafanaで始める可視化とアラート構築
クラウドネイティブ環境の安定稼働を実現する、PrometheusとGrafanaによる実践的な監視システムの構築と運用戦略を解説します。
Keywords: Prometheus, Grafana, クラウドネイティブ監視
目次
1. 背景/はじめに: なぜクラウドネイティブ監視が重要なのか?
2. Prometheus徹底解説: メトリクス収集の心臓部
3. Grafanaで実現する美しい可視化と洞察
4. 効果的なアラート構築: 障害を未然に防ぐ
5. 実践的な監視戦略と運用改善
6. まとめと将来展望
7. よくある質問 (FAQ)
1. 背景/はじめに: なぜクラウドネイティブ監視が重要なのか?
現代のITシステムは、クラウド技術の進化とともに劇的な変革を遂げています。特に「クラウドネイティブ」という言葉が示すように、マイクロサービス、コンテナ(Docker, Kubernetes)、Immutable Infrastructureといった技術が主流となり、システムの開発・運用はより俊敏かつスケーラブルになりました。しかし、その一方で、従来のモノリシックなシステムとは異なる新たな監視の課題も生まれています。
従来の監視は、主に個々のサーバーやアプリケーションの稼働状況を静的に監視するアプローチが中心でした。CPU使用率、メモリ使用量、ディスク空き容量といった基本的なリソースメトリクスに加え、特定のログパターンを監視することで、システムの状態を把握していました。しかし、クラウドネイティブ環境では、サービスが動的にスケールし、コンテナが頻繁に起動・停止し、ネットワーク構成も流動的です。このような環境では、個々のインスタンスを固定的に監視するだけでは不十分であり、システム全体を俯瞰し、サービスの健全性をリアルタイムで把握するための新しい監視アプローチが求められます。
例えば、2026年現在、多くの企業がクラウド移行を進めていますが、ある調査によれば、クラウド環境でのダウンタイムによる平均コストは、1時間あたり数千ドルから数十万ドルに達すると言われています。これは、サービス停止による直接的な収益損失だけでなく、顧客からの信頼失墜、ブランドイメージの低下、従業員の生産性低下など、多岐にわたる影響を含みます。特に、オンラインサービスやeコマース、金融システムなど、24時間365日の稼働が求められるシステムでは、わずかな停止時間も許されません。このような背景から、クラウドネイティブ環境における「監視」は、単なる障害検知ツールではなく、ビジネス継続性を保証し、サービス品質を維持するための不可欠な要素となっています。
ポイント
クラウドネイティブ環境では、システムの動的な変化に対応するため、従来の静的な監視手法では不十分です。サービス全体の健全性をリアルタイムで把握し、障害を未然に防ぐための新たな監視アプローチが不可欠であり、ビジネス継続性にとって極めて重要です。
PrometheusとGrafanaが選ばれる理由
この複雑なクラウドネイティブ監視の課題に対して、業界のデファクトスタンダードとして広く採用されているのが「Prometheus」と「Grafana」の組み合わせです。この二つのツールは、オープンソースでありながら非常に強力な機能を提供し、多くの企業でその有効性が実証されています。
Prometheusの強み
Pull型アーキテクチャ — 監視対象からメトリクスを「Pull」する方式で、監視対象の追加・削除が容易です。
多次元データモデル — メトリクスに任意のラベルを付与でき、柔軟なクエリと分析が可能です。
強力なクエリ言語 (PromQL) — 時系列データを高度に集計・変換し、複雑な条件でのアラート設定が可能です。
豊富なExporterエコシステム — 多くのミドルウェアやシステムに対応するExporterが提供されており、導入が容易です。
Grafanaの強み
多様なデータソース対応 — Prometheusだけでなく、Elasticsearch, InfluxDB, CloudWatchなど様々なデータソースを統合できます。
直感的で美しいダッシュボード — 豊富なパネルタイプとカスタマイズオプションで、視覚的に優れたダッシュボードを構築できます。
アラート機能 — Grafana上で直接アラート条件を設定し、様々な通知チャネルへ連携できます。
テンプレート変数 — 動的なダッシュボードを作成し、システムの規模や複雑さが増しても運用しやすくなります。
このブログ記事では、PrometheusとGrafanaを組み合わせたクラウドネイティブ監視システムの構築方法を、具体的な手順とコード例を交えながら詳しく解説していきます。あなたのシステムの安定稼働と運用改善に役立つ情報を提供できれば幸いです。
2. Prometheus徹底解説: メトリクス収集の心臓部
Prometheusは、SoundCloudで開発され、現在はCloud Native Computing Foundation (CNCF) のプロジェクトとして、Kubernetesとともにクラウドネイティブ監視のデファクトスタンダードとなっています。その最大の特徴は、監視対象からメトリクスを「Pull」するアーキテクチャと、強力なクエリ言語PromQLです。
Prometheusのアーキテクチャと主要コンポーネント
Prometheusのエコシステムは、いくつかの独立したコンポーネントから成り立っています。これらが連携することで、堅牢な監視システムを構築します。
主要コンポーネント
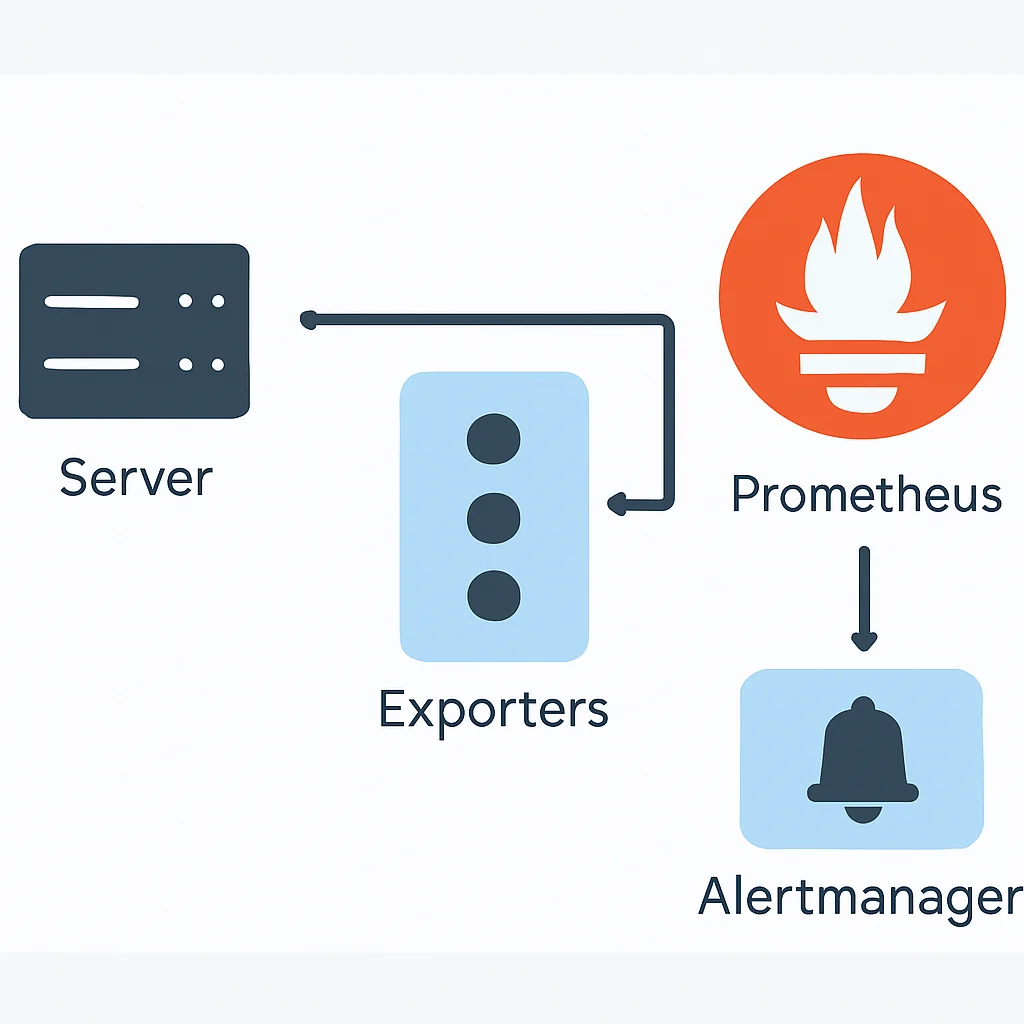
Prometheus Server — メトリクスを収集し、時系列データベースに保存するPrometheusの中核です。ターゲットを定期的にスクレイピング(Pull)し、PromQLによるクエリ処理、アラート評価を行います。
Exporter — 監視対象(OS、データベース、アプリケーションなど)のメトリクスをPrometheus形式(HTTPエンドポイント)で公開する軽量なプロセスです。例えば、Node ExporterはOSレベルのメトリクスを提供し、cAdvisorはコンテナのメトリクスを提供します。
Alertmanager — Prometheus Serverから送られてきたアラートを処理します。重複排除、グループ化、サイレンス、様々な通知チャネル(Slack, PagerDuty, Emailなど)へのルーティングを行います。
Pushgateway — 短期間しか存在しないジョブ(バッチ処理など)や、PrometheusのPull型アーキテクチャに合わないメトリクスを一時的に受け取り、Prometheus ServerがPullできるようにするコンポーネントです。
Prometheusのアーキテクチャは、各コンポーネントが疎結合であるため、柔軟な拡張と高可用性の実現を可能にします。特に、Service Discovery機能は、Kubernetesのような動的な環境において、新しいサービスやコンテナが立ち上がった際に自動的に監視対象に追加されるため、運用負荷を大幅に軽減します。
メトリクスタイプとその活用
Prometheusは、以下の4つの主要なメトリクスタイプをサポートしています。これらを適切に使い分けることで、システムの様々な側面を効果的に監視できます。
ポイント
Prometheusのメトリクスタイプを理解することは、正確なシステムの状態把握と適切なアラート設定の基礎となります。特にCounterとGaugeの使い分けは重要です。
1. Counter (カウンター)
単調増加する値で、リセットされることはありません。例えば、HTTPリクエストの総数、エラー発生回数などがこれに該当します。レート(1秒あたりの増加量)を計算する際に非常に有用です。
2. Gauge (ゲージ)
任意に増減する値で、現在の状態を示します。CPU使用率、メモリ使用量、現在の接続数、ディスク空き容量などがこれに該当します。
3. Histogram (ヒストグラム)
一定期間内の観測値の分布をサンプリングし、指定されたバケット(bucket)に分類して、その合計と観測回数を記録します。HTTPリクエストのレイテンシなど、分布を把握したい場合に利用します。サマリー統計(例えば99パーセンタイル)を計算できます。
4. Summary (サマリー)
クライアント側で計算された分位点(Quantile)と、観測値の合計および観測回数を記録します。ヒストグラムと似ていますが、分位点の計算がクライアント側で行われるため、Prometheusサーバーの負荷は低いですが、サーバー側で柔軟な集計がしにくいという特徴があります。
PromQLの基礎と実践的なクエリ例
PromQL (Prometheus Query Language) は、Prometheusが収集した時系列データを柔軟にクエリするための言語です。強力な集計関数や時系列演算子を備えており、複雑な監視シナリオに対応できます。
基本的なクエリは、メトリクス名とラベルセレクタで構成されます。例えば、http_requests_totalというメトリクスがあり、これにjob="api-server"とstatus="200"というラベルが付与されている場合を考えます。
コード解説
特定のジョブとステータスコードを持つHTTPリクエストの総数を取得する基本的なPromQLクエリです。
http_requests_total{job="api-server", status="200"}ここから、さらに複雑なクエリを見ていきましょう。
1. レートの計算 (Counterメトリクスに適用)
過去5分間の1秒あたりのHTTPリクエスト数を計算します。カウンターメトリクスにrate()関数を適用するのが一般的です。
コード解説
過去5分間のHTTPリクエストの平均レートを計算します。これにより、トラフィックの変動を把握できます。
rate(http_requests_total{job="api-server"}[5m])2. 集計 (Aggregation)
複数の時系列データを集計します。sum by (label)やavg by (label)がよく使われます。
コード解説
各インスタンスのCPUアイドル時間を合計し、CPU使用率を計算します。これは、特定のインスタンスグループ全体のCPU負荷を把握するのに役立ちます。
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)3. 比較演算子と論理演算子
PromQLでは、>, <, ==などの比較演算子や、and, or, unlessなどの論理演算子も利用できます。これらはアラート設定で特に重要になります。
ポイント
PromQLは非常に強力ですが、複雑なクエリはパフォーマンスに影響を与える可能性があります。必要なデータのみを抽出し、効率的なラベルセレクタを使用するよう心がけましょう。また、irate()とrate()の違いも理解しておくべきです。irate()は直近2つのデータポイント間の変化率を計算するため、突発的なスパイクを検出するのに適していますが、rate()は指定期間の平均変化率を計算するため、ノイズに強くトレンド把握に適しています。
Prometheusのインストールと基本的な設定
Prometheusのインストールは非常にシンプルです。公式ウェブサイトからバイナリをダウンロードし、設定ファイルを用意するだけで動作します。ここでは、Dockerを利用した簡単な起動方法と、基本的なprometheus.ymlの設定例を示します。
まず、prometheus.ymlというファイルを作成します。
コード解説
Prometheusの基本的な設定ファイルです。globalセクションでスクレイピング間隔などを定義し、scrape_configsで監視対象(ここではPrometheus自身とNode Exporter)を設定します。
global:
scrape_interval: 15s # 15秒ごとにメトリクスを収集
evaluation_interval: 15s # アラートルールを15秒ごとに評価
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # Prometheus自身のメトリクスを監視
- job_name: 'node_exporter'
static_configs:
- targets: ['node-exporter:9100'] # Node Exporterのメトリクスを監視 (docker-composeなどで連携する場合)次に、docker-compose.ymlを作成してPrometheusとNode Exporterを起動してみましょう。
コード解説
PrometheusとNode ExporterをDocker Composeで起動するための設定です。PrometheusがNode Exporterのメトリクスを収集できるように、ネットワーク内で連携させています。
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
depends_on:
- node-exporter
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
ports:
- "9100:9100"
command:
- '--path.rootfs=/host'
volumes:
- /:/host:ro,rslave
volumes:
prometheus_data:この設定でdocker-compose up -dを実行すれば、PrometheusサーバーとNode Exporterが起動し、Prometheusが自身のメトリクスとNode Exporterのメトリクスを収集し始めます。ブラウザでhttp://localhost:9090にアクセスすると、PrometheusのUIからメトリクスを確認したり、PromQLクエリを実行したりできます。
3. Grafanaで実現する美しい可視化と洞察
Prometheusがメトリクスを収集・保存するバックエンドである一方、Grafanaはそれらの時系列データを美しく、かつ分かりやすく可視化するためのフロントエンドツールです。Prometheusと連携することで、システムの健全性を一目で把握できるダッシュボードを構築し、問題発生時の迅速な原因特定を支援します。
Grafanaの役割とPrometheusとの連携
Grafanaは多様なデータソースに対応していますが、Prometheusとの連携は非常にスムーズです。GrafanaはPrometheusのHTTP APIを通じてPromQLクエリを発行し、その結果をグラフやテーブル、ゲージなどの様々な形式で表示します。この連携により、Prometheusの強力なクエリ能力を最大限に引き出しながら、視覚的に優れた監視ダッシュボードを実現できます。
ポイント
Grafanaは、単なる可視化ツールではなく、複数のデータソースを統合し、システムのあらゆる側面を一つのダッシュボードで俯瞰できる「オブザーバビリティプラットフォーム」としての役割も担います。これにより、複雑なクラウドネイティブ環境でも、迅速な状況把握と意思決定が可能になります。
GrafanaのインストールとPrometheusデータソースの追加
Prometheusと同様に、GrafanaもDockerで簡単に起動できます。先ほどのdocker-compose.ymlにGrafanaサービスを追加してみましょう。
コード解説
Prometheus、Node Exporterに加えてGrafanaサービスを定義したDocker Composeファイルです。GrafanaがPrometheusにアクセスできるように、同じネットワーク内で連携させています。
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
depends_on:
- node-exporter
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
ports:
- "9100:9100"
command:
- '--path.rootfs=/host'
volumes:
- /:/host:ro,rslave
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
depends_on:
- prometheus
volumes:
prometheus_data:
grafana_data:この状態でdocker-compose up -dを実行すると、Grafanaがhttp://localhost:3000で起動します。デフォルトのログイン情報はユーザー名admin、パスワードadminです(初回ログイン時にパスワード変更を求められます)。
ログイン後、左側のメニューから「Connections」>「Data sources」>「Add new data source」を選択し、「Prometheus」を選びます。設定画面で、URLをhttp://prometheus:9090と入力し、「Save & test」をクリックして接続を確認します。Docker Composeのサービス名がDNSとして機能するため、prometheusという名前でPrometheusにアクセスできます。
ダッシュボード作成の基本と実践例
データソースが設定できたら、いよいよダッシュボードを作成します。ダッシュボードは、複数のパネルで構成され、各パネルが特定のメトリクスを可視化します。
左メニューから「Dashboards」>「New dashboard」>「Add a new panel」を選択します。パネル設定画面で、データソースとして先ほど設定したPrometheusを選択し、PromQLクエリを入力します。
実践的なダッシュボード例
ここでは、Node Exporterから収集したOSレベルのメトリクスを可視化する例をいくつか紹介します。
1. CPU使用率 (Graphパネル)
コード解説
過去5分間のCPU使用率を計算し、グラフで表示します。インスタンスごとに色分けされるため、どのサーバーのCPU負荷が高いか一目で分かります。
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)2. メモリ使用率 (Gaugeパネル)
コード解説
現在のメモリ使用率を計算し、ゲージ形式で表示します。視覚的に現在の状態を把握するのに適しています。
100 - ((node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100)3. ディスク空き容量 (Tableパネル)
コード解説
各ファイルシステムのマウントポイントごとのディスク使用率をテーブル形式で表示します。詳細な情報を一覧で確認するのに適しています。
(node_filesystem_size_bytes{fstype!="rootfs", mountpoint!~"/(boot|var/lib/docker/overlay2)"} - node_filesystem_free_bytes{fstype!="rootfs", mountpoint!~"/(boot|var/lib/docker/overlay2)"}) / node_filesystem_size_bytes{fstype!="rootfs", mountpoint!~"/(boot|var/lib/docker/overlay2)"} * 100これらのパネルを組み合わせることで、システムの健全性を多角的に監視できるダッシュボードが完成します。Grafanaには、Grafana Labsが提供する公式のダッシュボードや、コミュニティで共有されている豊富なテンプレートが利用可能です。例えば、「Node Exporter Full」などのダッシュボードIDをインポートするだけで、すぐに利用を開始できます。

テンプレート変数と動的ダッシュボード
Grafanaの強力な機能の一つに「テンプレート変数」があります。これにより、同じダッシュボードを複数のインスタンスやサービスで再利用できるようになり、運用効率が大幅に向上します。
例えば、instanceラベルを使って、どのサーバーのメトリクスを表示するかをダッシュボード上部のドロップダウンで選択できるように設定できます。これにより、個々のサーバーのパフォーマンスを簡単に比較・分析できます。
ダッシュボード設定画面で「Dashboard settings」>「Variables」>「Add variable」を選択し、以下のように設定します。
- Name:
instance - Type:
Query - Data source:
Prometheus - Query:
label_values(node_cpu_seconds_total, instance) - Multi-value:
On(複数選択を可能にする) - Include All option:
On(すべてのインスタンスを選択するオプション)
この変数を設定したら、各パネルのPromQLクエリで$instanceを使用するように変更します。
コード解説
テンプレート変数を利用したCPU使用率のPromQLクエリです。ダッシュボード上部のドロップダウンで選択されたインスタンスのCPU使用率を表示します。
100 - (avg by (instance) (rate(node_cpu_seconds_total{instance=~"$instance", mode="idle"}[5m])) * 100)このようにテンプレート変数を活用することで、より柔軟で使いやすいダッシュボードを構築し、大規模なシステムでも効率的に監視できるようになります。例えば、マイクロサービス環境でサービスごとにダッシュボードを切り替えたり、特定のデプロイメント環境に絞って表示したりすることも可能です。
4. 効果的なアラート構築: 障害を未然に防ぐ
監視の目的は、単にシステムの状況を可視化するだけではありません。最も重要なのは、問題が発生する前に、あるいは発生した直後に検知し、適切な担当者に通知することで、障害の影響を最小限に抑えることです。「アラート」は、この目的を達成するための最も重要な機能の一つです。
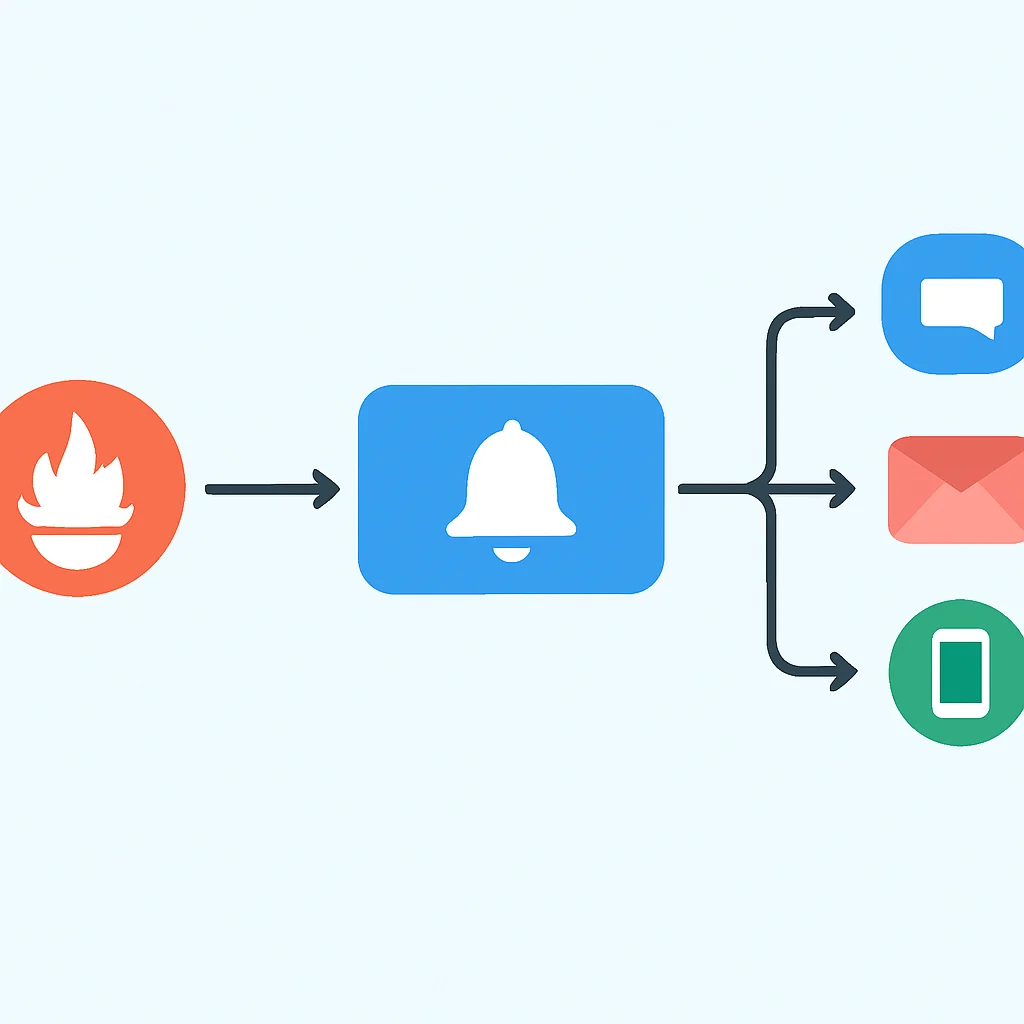
Prometheus Alertmanagerの役割と設定
Prometheus Serverは、設定されたアラートルールに基づいてメトリクスを評価し、条件を満たした場合にアラートを発報します。この発報されたアラートを受け取り、重複排除、グループ化、ルーティング、サイレンスなどの処理を行い、最終的にSlackやメール、PagerDutyなどの通知チャネルに送るのが「Alertmanager」の役割です。
ポイント
Alertmanagerは、アラートの「ノイズ」を減らし、適切なアラートを適切な担当者に適切なタイミングで届けるための重要な役割を担います。誤ったアラート設定や通知過多は、運用チームの疲弊につながるため、Alertmanagerの適切な設定は運用改善に直結します。
Alertmanagerの設定はalertmanager.ymlファイルで行います。主要な設定項目は以下の通りです。
receivers: アラートを受け取る通知チャネル(Slack, Emailなど)を定義します。routes: アラートのラベルに基づいて、どのアラートをどのレシーバーに送るかを決定します。グループ化やサイレンスもここで設定できます。global: 全体的な設定(例: デフォルトのSMTP設定)。
以下は、Slackに通知を送るための基本的なalertmanager.ymlの例です。
コード解説
Alertmanagerの基本的な設定ファイルです。Slackへの通知を設定し、全てのアラートをdefault-receiverにルーティングします。アラートのグループ化や抑制もここで定義できます。
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'cluster', 'service'] # これらのラベルでアラートをグループ化
group_wait: 30s # 新しいアラートを待つ時間
group_interval: 5m # グループ内のアラートを再送する間隔
repeat_interval: 1h # 解決されていないアラートを再送する間隔
receiver: 'default-receiver' # デフォルトのレシーバー
routes:
- match:
severity: 'critical'
receiver: 'critical-slack'
- match:
severity: 'warning'
receiver: 'warning-slack'
receivers:
- name: 'default-receiver'
slack_configs:
- channel: '#alerts-general'
api_url: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX' # Slack Webhook URL
send_resolved: true # アラート解決時に通知を送る
- name: 'critical-slack'
slack_configs:
- channel: '#alerts-critical'
api_url: 'https://hooks.slack.com/services/T00000000/B00000000/YYYYYYYYYYYYYYYYYYYYYYYY'
send_resolved: true
- name: 'warning-slack'
slack_configs:
- channel: '#alerts-warning'
api_url: 'https://hooks.slack.com/services/T00000000/B00000000/ZZZZZZZZZZZZZZZZZZZZZZZZ'
send_resolved: trueこのalertmanager.ymlをdocker-compose.ymlに追加し、Prometheusの設定ファイルでAlertmanagerのURLを指定することで、アラート通知システムが機能し始めます。
アラートルール(alert.rules.yml)の書き方
Prometheus Serverが評価するアラートルールは、alert.rules.ymlというファイルに記述します。このファイルは、Prometheusの設定ファイルprometheus.ymlから参照されます。
アラートルールは、以下の主要な要素で構成されます。
alert: アラートの名前。expr: アラートをトリガーするPromQLクエリ。このクエリが返す値が閾値を超えた場合にアラートが発生します。for: アラートが発報されるまでに、条件がどれくらいの期間継続する必要があるかを指定します。これにより、一時的なスパイクによる誤報を防ぎます。labels: アラートに付与される追加のラベル。Alertmanagerでのルーティングやグループ化に利用されます。annotations: アラートに関する追加情報。説明文やRunbookへのリンクなどを記述します。
以下は、CPU使用率が高すぎる場合にアラートを発報する例です。
コード解説
CPU使用率が80%を5分間継続して超えた場合にクリティカルアラートを発報するルールです。どのインスタンスで問題が発生しているか、具体的な説明も含まれます。
groups:
- name: general.rules
rules:
- alert: HighCPUUsage
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m
labels:
severity: critical
annotations:
summary: "CPU使用率が{{ $value }}%を超過しています (インスタンス: {{ $labels.instance }})"
description: "インスタンス {{ $labels.instance }} のCPU使用率が過去5分間、80%を超え続けています。システムパフォーマンスに影響が出る可能性があります。"このalert.rules.ymlをPrometheusのprometheus.ymlに以下のように追記します。
コード解説
Prometheus設定ファイルにアラートルールのファイルとAlertmanagerのURLを追記し、アラート評価と通知を有効にします。
# prometheus.yml
...
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093'] # AlertmanagerのURL (docker-composeのサービス名)
rule_files:
- "alert.rules.yml" # アラートルールファイルを指定
...これでPrometheusがアラートルールを評価し、条件に合致すればAlertmanager経由でSlackに通知が送られるようになります。アラートの重要度(
カテゴリー DevOps・クラウド、開発