

要約
PrometheusとGrafanaで始めるモダンな監視システム構築 2026年版
2026年におけるPrometheusとGrafanaを活用した、効果的なシステム監視システムの構築方法を実践的に解説します。
Keywords: Prometheus, Grafana, 監視
目次
1. 現代のシステム監視の重要性とPrometheus・Grafanaの役割
今日のデジタルサービスは、私たちの生活やビジネスに不可欠なものとなっています。オンラインショッピング、クラウドサービス、ソーシャルメディア、そして基幹業務システムに至るまで、その安定稼働は企業の信頼性や収益に直結します。2026年においても、この傾向はさらに加速しており、システムが一度停止すれば、顧客満足度の低下、機会損失、ブランドイメージの毀損など、計り知れない損害が発生する可能性があります。
このような背景から、システムの「監視(Monitoring)」は単なる障害検知の手段ではなく、サービスの品質を維持し、ユーザーエクスペリエンスを向上させるための戦略的な要素として位置づけられています。特に、マイクロサービスアーキテクチャやコンテナ、クラウドネイティブ技術の普及により、システムの構成はますます複雑化しています。従来の監視ツールでは対応しきれない、動的で分散された環境を効果的に監視するためには、よりモダンで柔軟なアプローチが求められます。
ポイント
2026年のモダンなシステム監視は、単なる障害検知を超え、サービスの品質維持とユーザーエクスペリエンス向上のための戦略的要素となっています。複雑化するシステム環境には、柔軟な監視ツールが不可欠です。
そこで注目されるのが、オープンソースの監視ツールであるPrometheus(プロメテウス)とGrafana(グラファナ)の組み合わせです。この二つのツールは、クラウドネイティブ環境における監視のデファクトスタンダードとして広く採用されており、その強力な連携によって、システムの「可観測性(Observability)」を大幅に向上させることができます。
Prometheusとは?メトリクス収集の心臓部
Prometheusは、システムやアプリケーションから「メトリクス(metrics)」と呼ばれる時系列データを収集・保存し、強力なクエリ言語「PromQL(プロムキューエル)」を使って分析・アラートを行うための監視システムです。Prometheusの最大の特徴は、監視対象からデータを「プル(Pull)」するアーキテクチャを採用している点にあります。これにより、監視対象側にエージェントをデプロイするだけで、手軽に監視を開始できます。
Prometheusは、特に以下の点で優れています。
- 柔軟なメトリクス収集: HTTPエンドポイントを介して様々なターゲットからメトリクスを収集できます。
- 強力なクエリ言語(PromQL): 複雑な集計や分析をリアルタイムで行うことができます。
- 豊富なエコシステム: さまざまなサービスに対応する「Exporter」が多数存在し、Kubernetesなどのクラウドネイティブ環境との親和性が非常に高いです。
- アラート機能: 定義したルールに基づいてアラートを発報し、Alertmanagerと連携して様々な通知チャネルに送信できます。
Grafanaとは?データ可視化の強力な武器
Grafanaは、Prometheusをはじめとする多様なデータソースからデータを取得し、美しくカスタマイズ可能なダッシュボードで可視化するためのツールです。直感的なUIで、複雑なメトリクスも一目で理解できる形に変換できます。Grafanaは、データソースの種類を問わず利用できる汎用性と、高い表現力が魅力です。
Grafanaの主な利点は以下の通りです。
- 多様なデータソース対応: Prometheusだけでなく、Loki(ログ)、Tempo(トレース)、Elasticsearch、MySQLなど、多くのデータソースに対応しています。
- 柔軟なダッシュボード: グラフ、テーブル、単一値表示など、様々なパネルタイプを組み合わせて情報豊富なダッシュボードを作成できます。
- アラート機能: Grafana自身でも、データに基づいてアラートを設定し、通知を送信する機能を持っています。
- コミュニティとテンプレート: 豊富なコミュニティダッシュボードテンプレートが公開されており、ゼロから作成する手間を省けます。
PrometheusとGrafanaを組み合わせることで、「メトリクス収集・保存・クエリ」と「データ可視化・アラート」という監視の主要な要素をカバーし、開発者や運用者がシステムの健全性を迅速に把握し、問題発生時には素早く対応できるモダンな監視システムを構築できます。
2. Prometheusの基礎:メトリクス収集とPromQL
Prometheusは、その独特なアーキテクチャと強力なクエリ言語によって、モダンな監視システムの中核をなします。ここでは、Prometheusがどのようにメトリクスを収集し、PromQLを使ってどのようにデータを分析するのかを深く掘り下げていきます。
Prometheusのアーキテクチャと動作原理
Prometheusの基本的なアーキテクチャは、監視対象のアプリケーションやサービスがHTTPエンドポイントを介してメトリクスを公開し、Prometheusサーバーが定期的にそのエンドポイントにアクセスしてメトリクスを「プル(Pull)」するというものです。このプル型モデルは、監視対象が動的に増減するクラウドネイティブ環境において非常に効果的です。
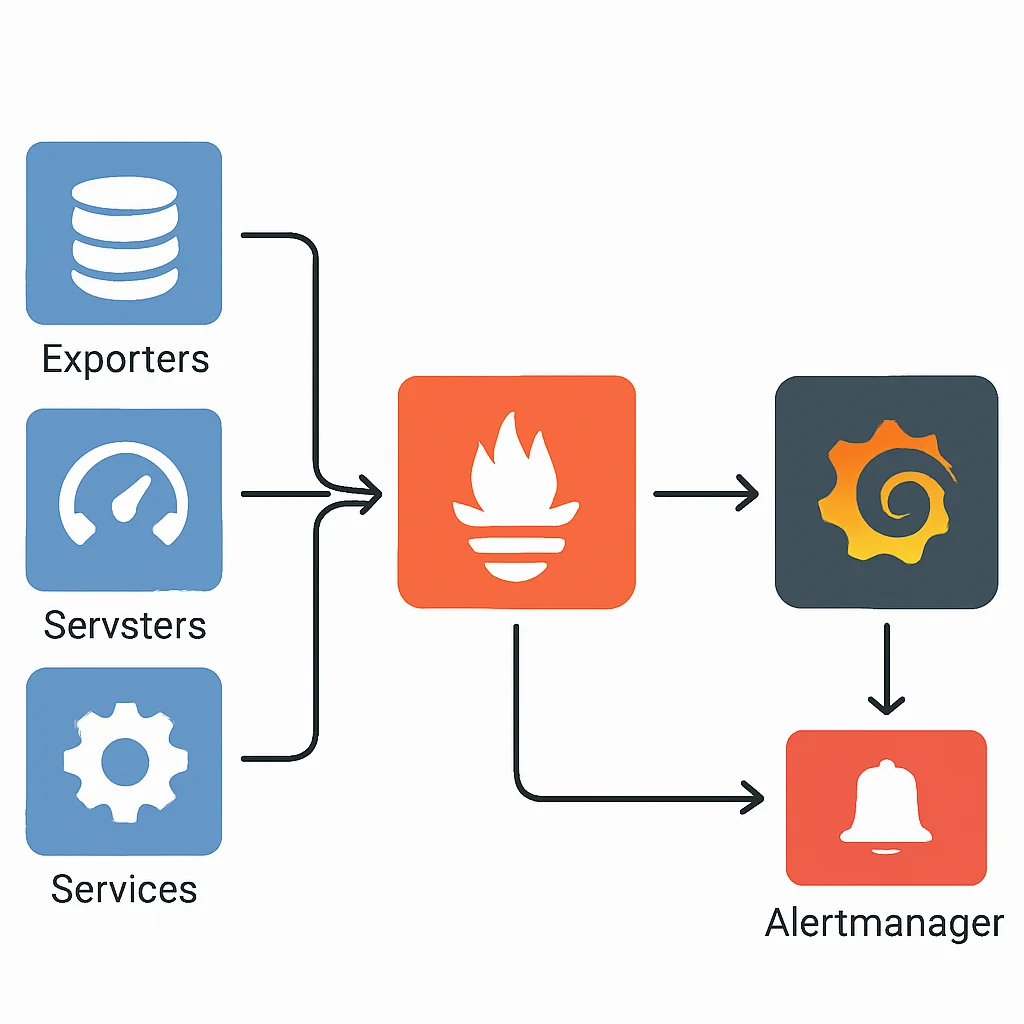
主要なコンポーネントは以下の通りです。
- Prometheus Server: メトリクスをプルし、時系列データベースに保存。PromQLエンジンとアラートルール評価エンジンも内蔵。
- Exporter: 既存のシステム(OS、データベース、Webサーバーなど)やアプリケーションからPrometheus形式のメトリクスを公開するエージェント。
- Pushgateway: 短命なジョブやバッチ処理など、Prometheusがプルしにくいメトリクスを一時的に受け取り、Prometheusに公開する役割。
- Alertmanager: Prometheusサーバーから受け取ったアラートを、グループ化、抑制、サイレンスなどの処理を行った上で、SlackやPagerDutyなどの通知チャネルに送信。
- Service Discovery: KubernetesやConsulなどの情報源から監視ターゲットを自動的に発見する機能。
Prometheusのメトリクスタイプ
Prometheusでは、メトリクスは特定のデータ型を持ち、それぞれ異なる用途に適しています。主なメトリクスタイプは以下の4つです。
Counter(カウンター)
特徴 — 単調に増加する数値。リセットされることはなく、システムの起動から現在までの累積値を表します。
ユースケース — HTTPリクエストの総数、エラーの総数、処理されたタスクの総数など。一定期間内の変化率を見る場合は、PromQLのrate()関数やirate()関数と組み合わせて使用します。
Gauge(ゲージ)
特徴 — 任意のタイミングで増減する数値。現在の状態や値を表します。
ユースケース — CPU使用率、メモリ使用量、ディスクの空き容量、現在のキューの長さ、アクティブなユーザー数など。現在のシステムの状態を把握するのに最適です。
Histogram(ヒストグラム)
特徴 — サンプリングされたイベントの分布(例: リクエストのレイテンシや応答時間)を観測し、指定されたバケットに分類します。合計値、カウント、バケットごとの観測値を提供します。
ユースケース — リクエストの応答時間の分布、データ転送量の分布など。特定の閾値を超えたリクエストの割合などを分析するのに使います。SLO/SLAの監視に非常に役立ちます。
Summary(サマリー)
特徴 — ヒストグラムに似ていますが、クライアント側で構成可能なパーセンタイル(Quantile)を計算します。合計値とカウントも提供します。
ユースケース — リクエストのレイテンシなど、分布を把握したいが、ヒストグラムのようにバケットを事前に定義するのが難しい場合。ただし、パーセンタイルの計算はクライアント側で行われるため、Prometheus側での集計には注意が必要です。
ポイント
メトリクスタイプを理解することは、適切な監視設計の第一歩です。Counterは累積値、Gaugeは現在の状態、Histogram/Summaryは分布の把握に使い分けます。
Exporterの活用:あらゆるシステムを監視対象に
Prometheusは、監視対象がPrometheus形式でメトリクスを公開していれば、何でも監視できます。しかし、既存のシステムやアプリケーションが最初からPrometheus形式のメトリクスを公開しているわけではありません。そこで活躍するのが「Exporter」です。Exporterは、特定のシステム(OS、データベース、Webサーバーなど)のメトリクスを収集し、Prometheusがプルできる形式でHTTPエンドポイントとして公開するプログラムです。
代表的なExporterをいくつかご紹介します。
- Node Exporter: Linux/UnixサーバーのOSレベルのメトリクス(CPU使用率、メモリ使用量、ディスクI/O、ネットワークトラフィックなど)を収集します。サーバー監視の基本となるExporterです。
- cAdvisor: DockerコンテナのCPU、メモリ、ネットワーク、ファイルシステムの使用状況などのリソースメトリクスを収集します。Kubernetes環境でよく利用されます。
- MySQL Exporter / PostgreSQL Exporter: 各データベースのパフォーマンスメトリクス(クエリ数、接続数、レプリケーション状態など)を収集します。
- Blackbox Exporter: 外部からHTTP/HTTPS、TCP、ICMPなどを用いてサービスのエンドポイントをプローブし、その可用性や応答時間を監視します。外部からの死活監視に利用されます。
Prometheusの設定ファイル prometheus.yml
Prometheusサーバーの動作は、prometheus.ymlというYAML形式の設定ファイルによって定義されます。このファイルには、グローバル設定、スクレイピング対象のジョブ定義、アラートルールのパスなどが記述されます。
コード解説
基本的なprometheus.ymlの設定例です。Prometheusサーバーのグローバル設定と、Node Exporterからのメトリクス収集ジョブを定義しています。
global:
# データをスクレイピングする間隔 (デフォルト15秒)
scrape_interval: 15s
# 評価ルールを評価する間隔 (デフォルト15秒)
evaluation_interval: 15s
# アラートルールが定義されたファイルを指定
alerting:
alertmanagers:
- static_configs:
- targets:
# Alertmanagerのアドレス (ここではDocker Composeのサービス名)
- alertmanager:9093
# ルールファイルを指定
rule_files:
- "alert.rules.yml"
# 監視対象のジョブ定義
scrape_configs:
# Prometheus自身を監視するジョブ
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # Prometheusサーバーのアドレス
# Node Exporterを監視するジョブ
- job_name: 'node_exporter'
static_configs:
- targets: ['node_exporter:9100'] # Node Exporterのアドレス (Docker Composeのサービス名)
labels:
env: production
datacenter: tokyo
この設定ファイルには、以下の重要な要素が含まれています。
global: 全てのスクレイピングジョブに適用されるデフォルト設定です。scrape_intervalはメトリクスを収集する頻度、evaluation_intervalはアラートルールを評価する頻度を定義します。alerting: Alertmanagerのインスタンスを指定します。Prometheusはここで指定されたAlertmanagerにアラートを送信します。rule_files: アラートルールが記述されたYAMLファイルを指定します。scrape_configs: 監視対象となるジョブのリストです。各ジョブにはjob_nameを指定し、static_configsで監視対象のターゲット(IPアドレスやホスト名とポート)を直接指定できます。ここでは、labelsを使って、メトリクスに任意のメタデータを付与しています。これはPromQLでのフィルタリングに非常に役立ちます。
PromQLの基礎:強力なクエリ言語
PromQL(Prometheus Query Language)は、Prometheusに保存された時系列データをリアルタイムでクエリし、分析するための強力な言語です。PromQLを習得することで、システムの健全性を深く洞察し、複雑な問題を特定できるようになります。
PromQLの基本は、メトリクス名とラベルセレクタです。メトリクスは、例えばnode_cpu_seconds_totalのように、システムの状態を表す名前を持ちます。ラベルは、そのメトリクスをさらに細かく分類するためのキーと値のペアで、例えば{mode="idle", cpu="0"}のように記述されます。
基本的なクエリ
コード解説
全てのPrometheusターゲットの稼働状況を示すメトリクスupをクエリします。値が1なら稼働中、0なら停止中を示します。
upコード解説
特定のジョブ(例: node_exporter)の稼働状況のみをフィルタリングして表示します。
up{job="node_exporter"}時間範囲セレクタと変化率関数
Prometheusは時系列データベースなので、特定の時間範囲でのデータの変化を分析することが重要です。時間範囲セレクタ(例: [5m]で過去5分間)を使って、その期間のデータを取得します。
コード解説
過去5分間のCPU利用率の変化率を計算します。node_cpu_seconds_totalはカウンターメトリクスであり、そのままでは累積値しかわかりません。そこでrate()関数を使って、1秒あたりの平均的な増加率を算出します。CPUがアイドル状態でない時間(mode!="idle")に限定することで、実際の負荷状況を把握します。
rate(node_cpu_seconds_total{mode!="idle"}[5m])このクエリは、過去5分間の各CPUコアのアイドル以外の時間における平均的な秒間使用率を返します。この値を合計し、CPUコア数で割ることで、システム全体の平均CPU使用率をパーセンテージで算出できます。
集約関数と演算子
PromQLは、複数の時系列データを集約するための強力な関数を提供します。sum(), avg(), max(), min()などがよく使われます。これらはby句やwithout句と組み合わせて、特定のラベルでグループ化したり、特定のラベルを除外して集約したりできます。
コード解説
各インスタンス(サーバー)ごとの過去5分間の平均CPU使用率をパーセンテージで計算します。これは、各サーバーの負荷状況を比較するのに役立ちます。
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)このクエリは、以下のステップでCPU使用率を計算します。
node_cpu_seconds_total{mode="idle"}[5m]: 過去5分間のCPUアイドル時間のカウンター値を取得します。rate(...): そのカウンターの1秒あたりの平均増加率、つまりアイドル時間の割合を計算します。avg by (instance) (...): 各instance(サーバー)ごとに、すべてのCPUコアのアイドル時間の割合を平均します。100 - (... * 100): アイドル時間の割合を100から引くことで、CPU使用率(パーセンテージ)を算出します。
PromQLは非常に強力ですが、慣れるまでには少し時間がかかります。しかし、一度習得すれば、システムのあらゆる側面を深く分析し、障害の根本原因を特定するための強力なツールとなるでしょう。
ポイント
PromQLは、メトリクス名とラベルセレクタ、そして豊富な関数を組み合わせて、時系列データを自由に分析できます。rate()やsum()といった関数は特に重要です。
3. Grafanaによる魅力的なダッシュボード構築と可視化
Prometheusが収集・保存した生データは、そのままでは人間にとって理解しにくいものです。そこでGrafanaの出番です。Grafanaは、Prometheusの強力なクエリ結果を、直感的で美しいグラフィカルなダッシュボードとして可視化する役割を担います。これにより、システムの健全性を一目で把握し、異常を素早く検知できるようになります。

Grafanaのデータソース設定
GrafanaがPrometheusからデータを取得するためには、まずデータソースとしてPrometheusを設定する必要があります。GrafanaのUIから簡単に設定できます。
データソース追加のステップ
1. Grafanaにログイン — デフォルトのユーザー名/パスワードは admin/admin です。
2. Configuration > Data sourcesへ移動 — サイドバーの歯車アイコンをクリックします。
3. “Add data source”をクリック — データソースの種類として”Prometheus”を選択します。
4. URLを設定 — Prometheusサーバーのアドレスを指定します。Docker Compose環境であれば http://prometheus:9090 となります。
5. “Save & test”をクリック — 接続が成功したことを確認します。
これでGrafanaがPrometheusからメトリクスをクエリできるようになりました。
ダッシュボードとパネルの作成
Grafanaのダッシュボードは、複数の「パネル」で構成されます。各パネルは、Prometheusのクエリ結果を特定の形式(グラフ、単一の数値、テーブルなど)で表示します。
基本的なダッシュボード構築手順
- ダッシュボードの作成: サイドバーの”+”アイコンをクリックし、”New dashboard”を選択します。
- パネルの追加: “Add new panel”をクリックします。
- データソースの選択: 先ほど設定したPrometheusデータソースを選択します。
- PromQLクエリの入力: “Metrics browser”または直接テキストボックスにPromQLクエリを入力します。
- パネルの可視化設定: パネルタイプ(Graph, Stat, Tableなど)を選択し、表示形式を調整します。
- パネルの保存: 設定が完了したら、パネルを保存し、ダッシュボード全体も保存します。
主要なパネルタイプと活用例
Graphパネル
概要 — 時系列データを線グラフで表示する最も一般的なパネルです。時間の経過に伴うメトリクスの変化を視覚的に捉えるのに最適です。
活用例 — CPU使用率、メモリ使用量、ネットワークトラフィック、リクエスト処理時間など、トレンドを追いたいメトリクス。
Statパネル (旧Singlestat)
概要 — 単一の数値を大きく表示し、現在の状態や重要な指標を強調します。閾値に基づいて色を変えることも可能です。
活用例 — 現在のCPU使用率の平均値、利用可能なメモリの割合、稼働中のサーバー数、エラーレートなど、瞬時の状況判断が必要なメトリクス。
Tableパネル
概要 — クエリ結果を表形式で表示します。複数のラベルや値を比較するのに便利です。
活用例 — 各サーバーの稼働状況(up/down)、各サービスのエラー件数、ディスク使用量が多いファイルシステムの一覧など。
ポイント
Grafanaでは、Graphパネルでトレンドを、Statパネルで現在の重要指標を、Tableパネルで詳細なリストを表示するなど、パネルタイプを使い分けることが重要です。
ダッシュボード変数の活用
Grafanaの「変数(Variables)」機能は、ダッシュボードの柔軟性と再利用性を飛躍的に向上させます。変数を使うことで、同じダッシュボードを複数のサーバーや環境で使い回したり、動的に表示内容を切り替えたりすることができます。
例えば、監視対象のサーバーが複数ある場合、各サーバーのCPU使用率を個別のダッシュボードで見るのではなく、一つのダッシュボードでサーバーを切り替えて見たいと考えるでしょう。このような場合に変数が役立ちます。
変数の設定例:サーバー選択ドロップダウン
1. Settings > Variablesへ移動 — ダッシュボードの歯車アイコンをクリックし、”Variables”を選択します。
2. “Add variable”をクリック — 変数タイプとして”Query”を選択します。
3. 名前とクエリを設定 — Name: instance, Query: label_values(node_cpu_seconds_total, instance)
4. パネルでの利用 — 各パネルのPromQLクエリで $instance を使用します。例: node_load1{instance="$instance"}
この設定により、ダッシュボード上部にサーバー選択のドロップダウンが表示され、選択したサーバーのメトリクスのみがパネルに表示されるようになります。これにより、運用者は必要な情報を素早くフィルタリングし、効率的に監視を行うことができます。
Grafana Lokiとの連携:ログとメトリクスを統合
現代の可観測性において、メトリクス、ログ、トレースの「三本柱」は不可欠です。Prometheusがメトリクスを扱うのに対し、Grafana Loki(ロキ)はログデータを効率的に収集・保存・検索するためのツールです。GrafanaはPrometheusとLokiの両方をデータソースとして扱えるため、メトリクスとログを同じダッシュボード上で関連付けて表示できます。

例えば、CPU使用率のスパイク(メトリクス)をグラフで確認した際に、その時間帯のログ(Loki)をすぐに参照し、何が起こっていたのかを詳細に調査することができます。この統合されたアプローチは、問題の根本原因を特定するまでの時間を大幅に短縮し、MTTD(Mean Time To Detect)とMTTR(Mean Time To Resolve)の改善に貢献します。
ポイント
GrafanaとLokiの連携により、メトリクスとログを統合して分析できるため、システムの可観測性が向上し、問題解決までの時間を短縮できます。これは、より複雑なクラウドネイティブ環境でのデバッグにおいて非常に強力な機能です。
4. 確実なアラート設定と運用戦略
監視システムは、問題が発生した際にそれを検知し、適切な担当者に通知する「アラート」機能がなければ意味がありません。Prometheusは強力なアラート機能を持っていますが、その通知を柔軟に制御し、アラート疲れを防ぐためには「Alertmanager」との連携が不可欠です。ここでは、PrometheusとAlertmanagerを使ったアラート設定と、その運用戦略について詳しく見ていきます。
Prometheus Alertmanagerの役割
Alertmanagerは、Prometheusサーバーから送信されたアラートを受け取り、重複排除、グルーピング、ルーティング、抑制、サイレンスなどの処理を行った上で、適切な通知チャネル(Slack, PagerDuty, Eメールなど)にアラートを送信する独立したコンポーネントです。
Alertmanagerの主な機能は以下の通りです。
- グルーピング: 同時に発生した多数のアラートを一つの通知にまとめて送信し、アラートの洪水を防ぎます。
- ルーティング: アラートのラベルに基づいて、特定のチームや個人、または異なる通知チャネルにアラートを振り分けます。
- 抑制(Inhibition): あるアラートが発報されている間、関連する他のアラートの通知を抑制します(例: クリティカルなアラートが出ている間は、そのサブコンポーネントの警告アラートを抑制)。
- サイレンス(Silence): メンテナンス時など、一時的に特定のアラートの通知を停止します。
アラートルールの記述方法 (alert.rules.yml)
Prometheusサーバーは、設定ファイルで指定されたrule_filesに記述されたアラートルールを定期的に評価し、条件が満たされた場合にアラートをAlertmanagerに送信します。
コード解説
Node Exporterが提供するメトリクスに基づいて、インスタンスがダウンしている場合とCPU使用率が高い場合にアラートを発報するルールです。
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m # 1分間継続したらアラート
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} is down"
description: "{{ $labels.instance }} が1分以上ダウンしています。原因を調査してください。"
- alert: HighCpuUsage
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m # 5分間継続したらアラート
labels:
severity: warning
annotations:
summary: "High CPU usage on {{ $labels.instance }}"
description: "{{ $labels.instance }} のCPU使用率が過去5分間で平均80%を超えています。"
- alert: HighMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 90
for: 5m
labels:
severity: warning
annotations:
summary: "High Memory usage on {{ $labels.instance }}"
description: "{{ $labels.instance }} のメモリ使用率が過去5分間で平均90%を超えています。"
各アラートルールには以下の要素が含まれます。
alert: アラートの名前。expr: アラートを発報する条件となるPromQLクエリ。このクエリが結果を返すと、アラートが発報されます。for: 条件が満たされてから、実際にアラートが発報されるまでの待機時間。これにより、一時的なスパイクによる誤報を防ぎます。labels: アラートに付与する追加のラベル。Alertmanagerでのルーティングやグルーピングに利用されます。ここではseverity(重要度)を設定しています。annotations: アラート通知に含まれる詳細情報(サマリーや説明)。{{ $labels.instance }}のように、アラートのラベル値を動的に埋め込むことができます。
Alertmanagerの設定と通知チャネル
Alertmanagerの設定はalertmanager.ymlファイルで行います。ここでは、アラートのルーティングや通知チャネル(レシーバー)を定義します。
コード解説
Alertmanagerの基本的な設定例です。全てのアラートをデフォルトのSlackチャネルに送信し、特定の重要度のアラートを別のチャネルにルーティングするよう設定しています。
global:
# Slack Webhook URL (実際のURLに置き換える)
slack_api_url: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX'
route:
receiver: 'default-slack' # デフォルトのレシーバー
group_by: ['alertname', 'instance', 'severity'] # これらのラベルでアラートをグループ化
group_wait: 30s # 最初の通知を送信するまでの待機時間
group_interval: 5m # グループ内の後続の通知を送信するまでの間隔
repeat_interval: 3h # アラートが解決されない場合に再度通知する間隔
# サブルート: severityがcriticalのアラートは別のSlackチャネルに送る
routes:
- match:
severity: 'critical'
receiver: 'critical-slack'
group_wait: 10s
repeat_interval: 1h
receivers:
- name: 'default-slack'
slack_configs:
- channel: '#alerts-general' # 一般的なアラートのSlackチャネル
send_resolved: true # 解決されたアラートも通知
- name: 'critical-slack'
slack_configs:
- channel: '#alerts-critical' # 重大なアラートのSlackチャネル
send_resolved: true
このalertmanager.ymlの主要な設定ポイントは以下の通りです。
global: 全てのレシーバーに適用される設定。ここではSlackのWebhook URLを設定しています。route: アラートのルーティングツリーのルートノードを定義します。group_byでアラートをまとめるラベルを指定し、group_wait,group_interval,repeat_intervalで通知の間隔を調整します。receivers: 実際に通知を受け取るエンドポイント(Slackチャネル、Eメールアドレスなど)と、その設定を定義します。
アラート運用のベストプラクティス
効果的なアラート設定は、単に条件を定義するだけではありません。運用面での考慮も重要です。
メリット
✓ アラート疲れの回避: 頻繁な誤報や重要でないアラートは、運用者の疲弊を招き、本当に重要なアラートを見逃す原因となります。適切なfor句の設定や、Alertmanagerのグルーピング機能を活用し、本当に必要なアラートのみを通知するように調整しましょう。
✓ Runbookの整備: 各アラートに対して、どのような対応を取るべきかをまとめた「Runbook(ランブック)」を準備しておくと、問題発生時の対応時間を大幅に短縮できます。アラート通知にRunbookへのリンクを含めるのも良いでしょう。
✓ 重要度に応じた通知: 全てのアラートを同じチャネルに送るのではなく、severityラベルなどを使って、重要度に応じた通知チャネルやエスカレーションパスを設定します。
✓ 定期的なアラートレビュー: アラートルールは一度設定したら終わりではありません。システムの変更や運用経験に基づいて、定期的にルールを見直し、改善していくことが重要です。
デメリット
✗ 閾値の調整の難しさ: 厳しすぎる閾値は誤報を、緩すぎる閾値は検知遅延を招きます。システムのベースラインを理解し、適切な閾値を見つけるには試行錯誤が必要です。
✗ スケーラビリティの課題: 大規模な環境では、PrometheusサーバーやAlertmanagerの負荷が高まる可能性があります。必要に応じて、PrometheusのHA構成や、Thanos/Mimirのような長期保存・クエリスケーリングソリューションの導入を検討する必要があります。
ポイント
アラートは、適切なタイミングで適切な情報を適切な担当者に届けることが重要です。アラート疲れを避け、運用効率を高めるために、グルーピング、ルーティング、そして定期的なレビューを徹底しましょう。
5. 実践!Docker Composeで監視システムを構築
PrometheusとGrafanaの理論的な側面を理解したところで、実際にこれらを動かす環境を構築してみましょう。DockerとDocker Composeを使えば、Prometheus、Grafana、Node Exporter、Alertmanagerといった複数のコンポーネントを簡単に連携させ、すぐに監視システムを立ち上げることができます。ここでは、基本的な監視システムを構築するステップを解説します。
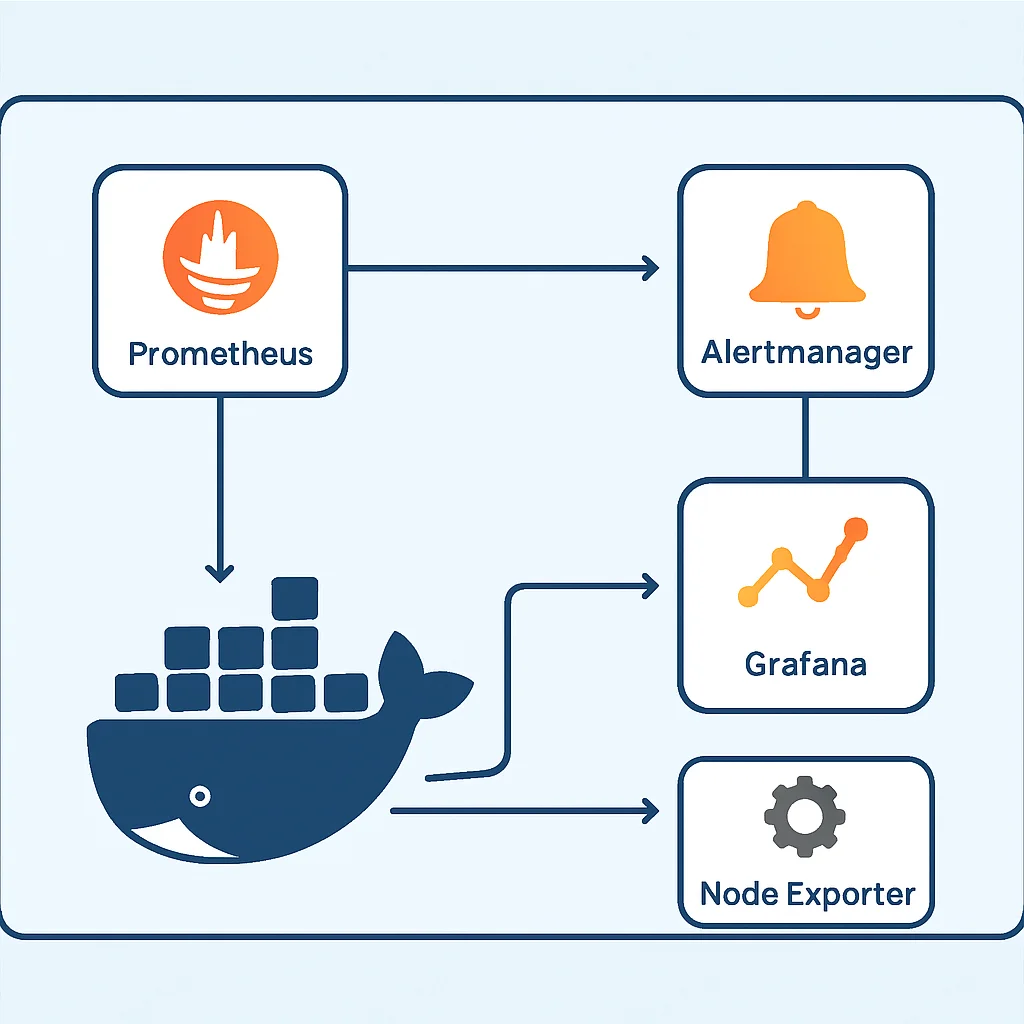
環境構築の前提条件
このガイドを進めるには、以下のソフトウェアがインストールされている必要があります。
- Docker Desktop: Docker EngineとDocker Composeが含まれています。Windows/macOSユーザーはこれをインストールしてください。
- Docker Engine & Docker Compose: Linuxユーザーはこれらを個別にインストールしてください。
ターミナルでdocker --versionとdocker compose versionを実行し、正しくインストールされていることを確認してください。
ディレクトリ構成と設定ファイルの準備
まず、プロジェクト用のディレクトリを作成し、その中にPrometheusとAlertmanagerの設定ファイルを配置します。
コード解説
以下のコマンドを実行して、必要なディレクトリと空の設定ファイルを作成します。
mkdir monitoring
cd monitoring
mkdir prometheus alertmanager grafana
touch prometheus/prometheus.yml
touch prometheus/alert.rules.yml
touch alertmanager/alertmanager.yml
touch docker-compose.yml
このコマンドで作成されるディレクトリ構造は以下のようになります。
monitoring/ ├── prometheus/ │ ├── prometheus.yml │ └── alert.rules.yml ├── alertmanager/ │ └── alertmanager.yml ├── grafana/ │ └── (Grafanaのデータが永続化されるディレクトリ) └── docker-compose.yml
設定ファイルの記述
前述のセクションで解説した内容に基づいて、各設定ファイルを記述します。ここでは、Node Exporterを追加して、ホストOSのメトリクスも監視できるようにします。
prometheus/prometheus.yml
コード解説
Prometheusの主要な設定ファイルです。Alertmanagerへのルーティングと、Prometheus自身、Node Exporter、そしてDockerホストのNode Exporterからのメトリクス収集ジョブを定義しています。
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
rule_files:
- "alert.rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['node_exporter:9100'] # Docker Composeサービス内のNode Exporter
labels:
env: development
instance_type: container
- job_name: 'host_node_exporter'
static_configs:
- targets: ['host.docker.internal:9100'] # DockerホストのNode Exporter
labels:
env: production
instance_type: host
ポイント: host.docker.internalはDocker Desktop環境でホストOSにアクセスするための特別なDNS名です。Linux環境でDockerを直接実行している場合は、ホストのIPアドレス(例: 172.17.0.1:9100)に置き換える必要があるかもしれません。
prometheus/alert.rules.yml
コード解説
システムがダウンした場合とCPU使用率が高い場合にアラートを発報する基本的なルールです。
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} is down"
description: "{{ $labels.instance }} が1分以上ダウンしています。原因を調査してください。"
- alert: HighCpuUsage
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "High CPU usage on {{ $labels.instance }}"
description: "{{ $labels.instance }} のCPU使用率が過去5分間で平均80%を超えています。"
alertmanager/alertmanager.yml
コード解説
Alertmanagerの設定ファイルです。ここではSlackへの通知を設定していますが、実際のWebhook URLに置き換える必要があります。テスト目的であれば、Slackのテスト用Webhook URLを使用できます。
global:
# ここを実際のSlack Webhook URLに置き換える!
# 例: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX'
slack_api_url: 'http://localhost:8080/slack_webhook_placeholder' # テスト用または実際のURLに置き換え
route:
receiver: 'default-slack'
group_by: ['alertname', 'instance', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receivers:
- name: 'default-slack'
slack_configs:
- channel: '#alerts-general'
send_resolved: true
docker-compose.yml
コード解説
Prometheus、Grafana、Node Exporter、Alertmanagerの4つのサービスを定義するDocker Composeファイルです。各サービスの設定、ボリュームマウント、ポートマッピングを行っています。
version: '3.8'
services:
prometheus:
image: prom/prometheus:v2.50.1 # 2026年時点での安定版に近いバージョンを指定
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/alert.rules.yml:/etc/prometheus/alert.rules.yml
- prometheus_data:/prometheus # メトリクスデータを永続化
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
depends_on:
- node_exporter # Node Exporterより後に起動
- alertmanager
restart: unless-stopped
grafana:
image: grafana/grafana:10.4.2 # 2026年時点での安定版に近いバージョンを指定
container_name: grafana
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana # Grafanaデータを永続化
- ./grafana/provisioning:/etc/grafana/provisioning # データソースやダッシュボードのプロビジョニング
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
- GF_SERVER_ROOT_URL=http://localhost:3000
depends_on:
- prometheus
restart: unless-stopped
node_exporter:
image: prom/node-exporter:v1.7.0 # 2026年時点での安定版に近いバージョンを指定
container_name: node_exporter
ports:
- "9100:9100"
command:
- '--path.rootfs=/host'
volumes:
- /proc:/host/proc:ro # ホストのプロセス情報を読み取り専用でマウント
- /sys:/host/sys:ro # ホストのシステム情報を読み取り専用でマウント
- /:/host:ro,rslave # ホストのルートファイルシステムを読み取り専用でマウント
pid: host # ホストのPID namespaceを使用
restart: unless-stopped
alertmanager:
image: prom/alertmanager:v0.27.0 # 2026年時点での安定版に近いバージョンを指定
container_name: alertmanager
ports:
- "9093:9093" # AlertmanagerのUI
- "9094:9094" # Prometheusからの受信ポート
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
- alertmanager_data:/alertmanager # データを永続化
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/alertmanager'
restart: unless-stopped
volumes:
prometheus_data:
grafana_data:
alertmanager_data:
Node Exporterの設定でpid: hostとvolumesを適切に設定することで、コンテナ内のNode ExporterがホストOSのメトリクスを収集できるようになります。これは、DockerコンテナとしてNode Exporterを実行しつつ、ホストOSを監視する一般的な方法です。
監視システムの起動と確認
全てのファイルが準備できたら、monitoringディレクトリで以下のコマンドを実行して、システムを起動します。
コード解説
Docker Composeを使って、定義されたすべてのサービスをバックグラウンドで起動します。
docker compose up -d数分待つと、各サービスが起動し、コンテナが実行状態になります。以下のURLにアクセスして、各コンポーネントの動作を確認しましょう。
- Prometheus UI: PrometheusサーバーのWebインターフェース。Status > Targetsで全ての監視ターゲットが”UP”になっていることを確認します。
- Grafana UI: GrafanaのWebインターフェース。デフォルトのログイン情報はadmin/adminです。ログイン後、Prometheusデータソースが正しく設定されていることを確認し、ダッシュボードを作成してみましょう。
- Node Exporter: http://localhost:9100/metrics にアクセスすると、生メトリクスデータが表示されます。
ポイント
Docker Composeを使用することで、Prometheus、Grafana、Alertmanager、Node Exporterといった複雑な監視スタックを数分で立ち上げることができます。これにより、手軽にモダンな監視環境を体験し、学習を進めることが可能です。
よくある質問 (FAQ)
Q. PrometheusとGrafanaはなぜ人気があるのですか?
A. Prometheusは強力な時系列データベースとPromQLによる柔軟なクエリ機能、Grafanaは多様なデータソースに対応した美しい可視化機能が評価されています。両者ともにオープンソースであり、クラウドネイティブ環境との親和性が高く、豊富なコミュニティとエコシステムが利用できるため、モダンな監視のデファクトスタンダードとなっています。
Q. Prometheusはログ監視もできますか?
A. Prometheusは主にメトリクス(数値データ)の監視に特化しており、ログ監視には直接対応していません。ログ監視には、Grafana LokiやElasticsearch/Kibanaなどの専用ツールを組み合わせるのが一般的です。Grafanaはこれらのログツールと連携して、メトリクスとログを統合的に可視化できます。
Q. Grafanaでアラートを設定するメリットは何ですか?
A. GrafanaはPrometheusとは独立してアラート機能を持っており、複数のデータソースからのデータを統合してアラート条件を定義できる点が大きなメリットです。例えば、PrometheusのメトリクスとLokiのログを組み合わせた複雑なアラート条件を設定したり、Grafanaのダッシュボード上で直接アラートの状態を確認したりできます。
Q. PromQLは難しいですか?
A. PromQLは独特の構文を持つため、初めて触れる方には少し難しく感じるかもしれません。しかし、基本的なメトリクス名とラベル、そしてrate()やsum()などの主要な関数を理解すれば、強力な分析ツールとして活用できます。実践的な演習を重ねることで、効率的に習得できます。
Q. 監視システムの構築で最も重要なことは何ですか?
A. 最も重要なのは、何を監視し、なぜ監視するのかという目的を明確にすることです。単にツールを導入するだけでなく、システムのボトルネックやビジネスへの影響を考慮し、適切なメトリクスを選択し、意味のあるアラートを設定することが不可欠です。また、アラート疲れを防ぐための運用設計も非常に重要になります。
7. まとめと今後の展望
本記事では、2026年におけるモダンな監視システムの構築において、PrometheusとGrafanaがいかに強力なツールであるかをご紹介しました。Prometheusによる時系列メトリクスの収集とPromQLによる柔軟な分析、そしてGrafanaによる直感的で美しい可視化は、今日の複雑なシステム環境において、開発者や運用者がシステムの健全性を維持し、問題を迅速に解決するための不可欠な要素です。
Docker Composeを使った実践的な構築手順を通じて、実際に手を動かしながらこれらのツールを体験していただけたことと思います。Node ExporterでホストOSのメトリクスを収集し、Prometheusで保存・クエリし、Grafanaでダッシュボードを作成する一連の流れは、監視システムの基本を学ぶ上で非常に重要です。
ポイント
PrometheusとGrafanaの組み合わせは、メトリクス収集、分析、可視化、アラートの全てをカバーする強力な監視システムを提供します。Docker Composeを使えば、このモダンな監視スタックを迅速に構築し、実践的な学習を始めることができます。
今後の展望
監視の世界は常に進化しています。2026年以降も、以下のようなトレンドが注目されるでしょう。
- AI/MLによる異常検知: 監視データから機械学習を用いて異常パターンを自動で検知し、アラートの精度を向上させるアプローチがさらに普及するでしょう。
- eBPFの活用: カーネルレベルでの詳細な可観測性を実現するeBPF(extended Berkeley Packet Filter)は、より低オーバーヘッドで豊富なメトリクスやトレースを収集する手段として期待されています。
- 分散トレースの普及: JaegerやOpenTelemetryといった分散トレースツールがPrometheusやLokiとさらに密接に連携し、複雑なマイクロサービス間のリクエストフローを可視化することで、障害調査をより効率的にするでしょう。
- OpenTelemetryの標準化: メトリクス、ログ、トレースの収集とエクスポートを標準化するOpenTelemetryは、ベンダーロックインを避け、より柔軟な可観測性プラットフォームの構築を促進します。PrometheusもOpenTelemetryとの連携を強化しています。
これらの進化の波に対応するためにも、PrometheusとGrafanaの基本的な知識と実践的なスキルは、今後もDevOpsエンジニアやSREにとって非常に価値のあるものとなるでしょう。ぜひ、本記事をきっかけに、ご自身のシステム監視をさらにモダンで堅牢なものにしてください。
最後までお読みいただきありがとうございます
PrometheusとGrafanaを使ったモダンな監視システムの構築は、複雑化するIT環境において、サービスの安定稼働と迅速な問題解決に不可欠なスキルです。本記事が皆様のシステム運用の一助となれば幸いです。
ご質問があればコメントでどうぞ。