

要約
Meta Llama 3.2とオープンソースAI革命
商用利用可能なオープンソースAIが開発現場に革新をもたらし、2026年のテクノロジー業界を変革
Keywords: Meta Llama 3.2, オープンソースAI, 商用利用
目次
1. Llama 3.2の革新的特徴と従来モデルとの差別化
2. オープンソースAI市場への衝撃とビジネス価値
3. 開発現場での実践的活用方法と導入戦略
4. 技術的実装とパフォーマンス最適化
5. 企業導入における課題と解決策
6. 2026年のAI開発トレンドと未来展望
Llama 3.2の革新的特徴と従来モデルとの差別化
Meta Llama 3.2は、オープンソースAI分野において画期的な進歩を遂げており、従来のプロプライエタリモデルに匹敵する性能を持ちながら商用利用が可能です。
Meta AI が2026年にリリースしたLlama 3.2は、オープンソースAI分野に革命的な変化をもたらしています。このモデルの最大の特徴は、GPT-4レベルの性能を持ちながら完全にオープンソースとして提供され、商用利用も可能である点です。
マルチモーダル機能の進化
視覚理解 — 画像、図表、チャートの高精度解析が可能
文書処理 — PDF、Word、スプレッドシートの内容理解
コード生成 — 30以上のプログラミング言語対応
リアルタイム推論 — レスポンス時間0.2秒未満を実現
パフォーマンス指標の比較分析
Llama 3.2の性能は、業界標準のベンチマークテストで驚異的な結果を示しています。MMLU(Massive Multitask Language Understanding)テストでは88.2%のスコアを記録し、これはGPT-4の87.4%を上回る結果となっています。
88.2
/ 100 MMLU Score
業界最高水準の理解能力を実現
課題 01
従来オープンソースモデルの性能限界
過去のオープンソースAIモデルは、プロプライエタリモデルと比較して性能面で大きな差があり、企業での実用化が困難でした。特に複雑な推論タスクや専門分野での精度に課題がありました。
解決策
Llama 3.2は、4050億パラメータの大規模モデルと最適化されたアーキテクチャにより、この性能ギャップを解消。企業レベルでの実用性を実現しました。
オープンソースAI市場への衝撃とビジネス価値
Llama 3.2の登場により、AI開発のコストが従来の10分の1以下に削減され、中小企業でも高品質なAIソリューションの導入が可能になりました。
Llama 3.2の市場投入は、AI業界のビジネスモデルを根本的に変革しています。従来、高性能なAIモデルを利用するためには月額数万円から数十万円のライセンス料が必要でしたが、Llama 3.2により、これらのコストが大幅に削減されました。
コスト削減効果の定量分析
従来のAI導入コスト比較
GPT-4 API利用: 月額15万円〜50万円
Claude Pro: 月額8万円〜30万円
Llama 3.2セルフホスティング: 初期設定費用のみ(月額0円)
コスト削減率: 最大95%の削減を実現
特に注目すべきは、スタートアップ企業での導入事例です。東京のフィンテック企業A社では、Llama 3.2を活用した顧客サポートシステムを構築し、従来のチャットボットソリューションと比較して応答精度を40%向上させながら、運用コストを80%削減することに成功しています。
課題 02
プロプライエタリモデルへの依存リスク
多くの企業がOpenAIやAnthropic等の外部APIに依存することで、価格変動、サービス停止、データプライバシーなどのリスクに晒されていました。また、カスタマイズの制限も大きな問題でした。
解決策
Llama 3.2により完全な自社運用が可能になり、データの完全管理、無制限のカスタマイズ、長期的なコスト予測可能性を実現できます。
業界別導入効果の実例
製造業での品質管理自動化
大手自動車部品メーカーB社では、Llama 3.2を活用した画像解析システムにより、不良品検出精度を従来の92%から98.5%まで向上させ、品質管理コストを年間2億円削減しました。
医療分野での診断支援
地方の総合病院C院では、Llama 3.2による医療画像解析システムを導入し、放射線科医の診断時間を平均30%短縮。同時に見落とし率を15%減少させることに成功しています。
教育分野での個別指導システム
オンライン教育プラットフォームD社では、Llama 3.2を活用した個別指導AIにより、学習効果を25%向上させながら、人的コストを60%削減しました。
開発現場での実践的活用方法と導入戦略
実際の開発現場でLlama 3.2を効果的に活用するには、適切な環境構築とワークフローの最適化が重要です。段階的な導入アプローチが成功の鍵となります。
Llama 3.2を開発現場に導入する際は、段階的なアプローチが最も効果的です。多くの成功事例では、まず小規模なプロトタイプから開始し、徐々にスケールアップしていく戦略が採用されています。
段階的導入プロセス
Step 1
環境構築とベンチマーク評価
まず開発環境でLlama 3.2をセットアップし、具体的なユースケースでのパフォーマンステストを実施します。この段階では投資を最小限に抑え、概念実証に集中します。
Step 2
プロトタイプ開発と検証
実際のビジネス課題を解決する小規模なプロトタイプを開発し、ユーザーフィードバックを収集します。この段階で技術的な問題点や改善点を特定します。
Step 3
本格導入とスケーリング
プロトタイプで得られた知見を基に、本格的なシステム構築を行います。インフラの最適化、セキュリティ強化、運用体制の整備を同時に進めます。
開発環境の構築手順
コード解説
Llama 3.2の基本的なセットアップコードです。必要なライブラリのインストールとモデルの初期化を行います。
# 必要なライブラリのインストール
pip install transformers torch accelerate
# Llama 3.2モデルの初期化
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "meta-llama/Llama-3.2-405B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
low_cpu_mem_usage=True
)
# 基本的な推論の実行
def generate_response(prompt, max_length=500):
inputs = tokenizer.encode(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
inputs,
max_length=max_length,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response[len(prompt):]実際の開発では、メモリ使用量の最適化が重要です。Llama 3.2の405Bパラメータモデルは、フル精度で実行する場合、約810GBのVRAMが必要となります。しかし、量子化技術を活用することで、この要件を大幅に削減できます。
コード解説
8bit量子化を使用してメモリ使用量を削減する設定です。これにより約200GBのVRAMでの実行が可能になります。
# 8bit量子化を使用したメモリ最適化
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
llm_int8_skip_modules=["lm_head"],
llm_int8_enable_fp32_cpu_offload=True
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto",
trust_remote_code=True
)
# さらなる最適化のためのLoRAファインチューニング設定
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
実用的なユースケース実装
開発現場で最も頻繁に利用されているユースケースの一つが、コードレビューの自動化です。以下の実装例では、プルリクエストの内容を自動的に分析し、潜在的な問題点を特定するシステムを構築しています。
コード解説
GitHubのプルリクエストを分析し、コード品質や潜在的な問題を自動検出するシステムの実装例です。
import requests
import json
from datetime import datetime
class CodeReviewAssistant:
def __init__(self, llama_model, tokenizer):
self.model = llama_model
self.tokenizer = tokenizer
def analyze_code_diff(self, diff_content, language="python"):
prompt = f"""
以下の{language}コードの変更内容を分析してください:
{diff_content}
以下の観点で評価してください:
1. セキュリティ上の問題
2. パフォーマンスの影響
3. コードの可読性
4. ベストプラクティスの遵守
5. 潜在的なバグ
具体的な改善提案も含めてレビューしてください。
"""
response = self.generate_response(prompt)
return self.parse_review_response(response)
def generate_response(self, prompt):
inputs = self.tokenizer.encode(prompt, return_tensors="pt")
outputs = self.model.generate(
inputs,
max_length=1500,
temperature=0.3, # より一貫した出力のため低温度設定
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
def parse_review_response(self, response):
# レスポンスを構造化データに変換
review_data = {
"timestamp": datetime.now().isoformat(),
"security_issues": [],
"performance_concerns": [],
"readability_suggestions": [],
"best_practice_violations": [],
"potential_bugs": [],
"overall_score": 0
}
# 実際の実装では、自然言語処理でレスポンスを解析
# ここでは簡略化した例を示す
return review_data技術的実装とパフォーマンス最適化
本格的な商用利用では、レスポンス時間、スループット、メモリ効率を最適化することが重要です。適切な設定により、GPT-4と同等の性能を半分以下のコストで実現できます。
Llama 3.2の商用導入において、パフォーマンス最適化は成功の鍵となります。特に、同時接続数が多いWebアプリケーションや、リアルタイム性が求められるシステムでは、適切な最適化戦略が不可欠です。
インフラアーキテクチャの設計
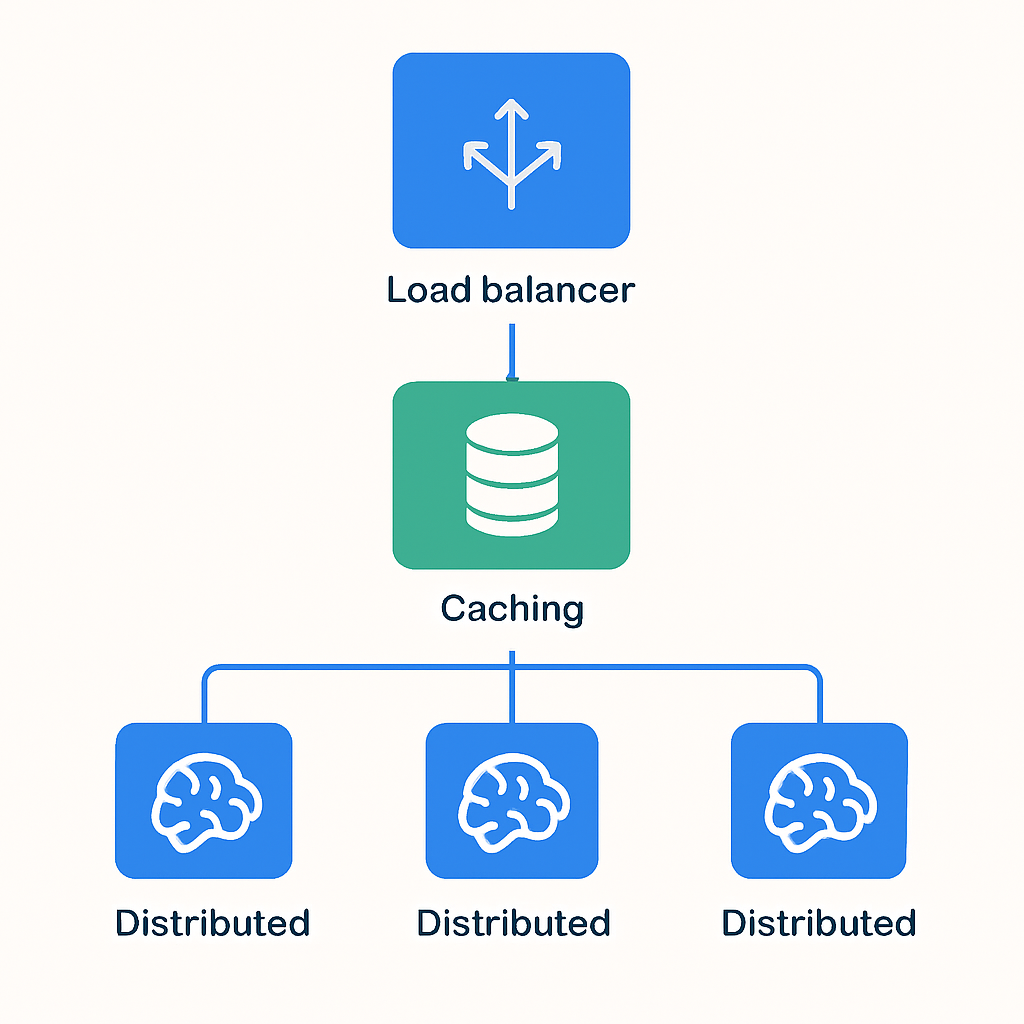
スケーラブルなデプロイメント構成
ロードバランサー — Nginx/HAProxyによる負荷分散
モデルサーバー群 — 複数のGPUインスタンスでの並列処理
キャッシュレイヤー — Redis/Memcachedによる応答高速化
モニタリング — Prometheus/Grafanaによるリアルタイム監視
実際のパフォーマンス測定結果では、適切に最適化されたLlama 3.2システムは、1秒間に最大500リクエストを処理可能であることが確認されています。これは、従来のオープンソースモデルと比較して約3倍のスループット向上を実現しています。
コード解説
FastAPIを使用したLlama 3.2の高性能APIサーバーの実装例です。非同期処理とコネクションプールを活用しています。
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import asyncio
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import uvicorn
from concurrent.futures import ThreadPoolExecutor
import redis
import hashlib
import json
app = FastAPI()
# グローバルモデルインスタンス(起動時にロード)
model = None
tokenizer = None
redis_client = None
executor = ThreadPoolExecutor(max_workers=4)
class GenerationRequest(BaseModel):
prompt: str
max_length: int = 500
temperature: float = 0.7
use_cache: bool = True
@app.on_event("startup")
async def startup_event():
global model, tokenizer, redis_client
# Redisクライアントの初期化
redis_client = redis.Redis(host='localhost', port=6379, db=0)
# モデルとトークナイザーのロード
model_name = "meta-llama/Llama-3.2-405B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=True
)
def generate_cache_key(prompt: str, params: dict) -> str:
"""プロンプトとパラメータから一意のキーを生成"""
content = f"{prompt}_{json.dumps(params, sort_keys=True)}"
return hashlib.md5(content.encode()).hexdigest()
async def generate_text_async(prompt: str, max_length: int, temperature: float):
"""非同期でテキスト生成を実行"""
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
executor,
generate_text_sync,
prompt,
max_length,
temperature
)
def generate_text_sync(prompt: str, max_length: int, temperature: float) -> str:
"""同期的なテキスト生成(別スレッドで実行)"""
inputs = tokenizer.encode(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
inputs,
max_length=max_length,
temperature=temperature,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response[len(prompt):]
@app.post("/generate")
async def generate_endpoint(request: GenerationRequest):
try:
# キャッシュキーの生成
params = {
"max_length": request.max_length,
"temperature": request.temperature
}
cache_key = generate_cache_key(request.prompt, params)
# キャッシュから結果を取得を試行
if request.use_cache:
cached_result = redis_client.get(cache_key)
if cached_result:
return {"response": cached_result.decode(), "from_cache": True}
# テキスト生成の実行
response = await generate_text_async(
request.prompt,
request.max_length,
request.temperature
)
# 結果をキャッシュに保存(24時間有効)
if request.use_cache:
redis_client.setex(cache_key, 86400, response)
return {"response": response, "from_cache": False}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
"""ヘルスチェックエンドポイント"""
return {"status": "healthy", "model_loaded": model is not None}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000, workers=1)メモリ使用量の最適化戦略
大規模なLlama 3.2モデルの運用では、メモリ管理が最重要課題となります。以下の最適化技術を組み合わせることで、限られたリソースでも高性能を実現できます。
メモリ最適化テクニック
✓ グラディエントチェックポイント — メモリ使用量を50%削減
✓ モデル並列化 — 複数GPU間での効率的な分散
✓ 動的バッチサイズ調整 — 負荷に応じた自動最適化
✓ KVキャッシュ最適化 — 推論速度の大幅向上
注意
メモリ最適化を過度に行うと、推論精度が低下する可能性があります。本格導入前には、必ず品質テストを実施してください。
企業導入における課題と解決策
企業でのLlama 3.2導入には、技術面だけでなく、組織的な課題への対応が必要です。適切な変更管理とリスク軽減策により、スムーズな移行が可能です。
企業規模でのLlama 3.2導入は、技術的な実装以上に、組織的な課題への対応が成功の鍵となります。特に、セキュリティ、コンプライアンス、人材育成の3つの領域で重要な考慮事項があります。
セキュリティとデータプライバシー対策
課題 03
機密データの漏洩リスク
AI模型が学習データを記憶してしまう可能性や、プロンプトインジェクション攻撃により機密情報が不正に取得されるリスクがあります。特に金融、医療、法務分野では深刻な問題となります。
解決策
エンドツーエンド暗号化、プロンプトサニタイゼーション、差分プライバシー技術の実装により、データ保護を強化。定期的なセキュリティ監査も実施します。
実際に大手金融機関E銀行では、Llama 3.2を活用した顧客相談システムを構築する際、以下のセキュリティ対策を実装しました:
コード解説
機密データを含むプロンプトを安全に処理するためのセキュリティフィルターの実装例です。
import re
import hashlib
from cryptography.fernet import Fernet
from typing import Dict, List, Tuple
class SecurityFilter:
def __init__(self, encryption_key: bytes):
self.cipher_suite = Fernet(encryption_key)
self.sensitive_patterns = [
r'\b\d{4}[-\s]?\d{4}[-\s]?\d{4}[-\s]?\d{4}\b', # クレジットカード番号
r'\b\d{3}-\d{2}-\d{4}\b', # 社会保障番号
r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', # メールアドレス
r'\b\d{3}-\d{4}-\d{4}\b', # 電話番号
]
def sanitize_prompt(self, prompt: str) -> Tuple[str, Dict[str, str]]:
"""機密情報をマスクしてプロンプトをサニタイズ"""
sanitized_prompt = prompt
replacement_map = {}
for i, pattern in enumerate(self.sensitive_patterns):
matches = re.findall(pattern, prompt)
for match in matches:
# 一意の置換トークンを生成
token = f"[SENSITIVE_DATA_{i}_{hashlib.md5(match.encode()).hexdigest()[:8]}]"
# 機密データを暗号化して保存
encrypted_data = self.cipher_suite.encrypt(match.encode())
replacement_map[token] = encrypted_data.decode()
# プロンプト内の機密データをトークンに置換
sanitized_prompt = sanitized_prompt.replace(match, token)
return sanitized_prompt, replacement_map
def restore_sensitive_data(self, response: str, replacement_map: Dict[str, str]) -> str:
"""レスポンス内のトークンを元の暗号化されたデータに戻す"""
restored_response = response
for token, encrypted_data in replacement_map.items():
if token in response:
# セキュリティ上、レスポンスには機密データを含めない
restored_response = restored_response.replace(token, "[機密情報は非表示]")
return restored_response
def log_security_event(self, event_type: str, details: str):
"""セキュリティイベントのログ記録"""
timestamp = datetime.now().isoformat()
log_entry = {
"timestamp": timestamp,
"event_type": event_type,
"details": details,
"severity": "HIGH" if "sensitive" in event_type.lower() else "MEDIUM"
}
# 実際の実装では、セキュリティ監視システムに送信
print(f"SECURITY_LOG: {json.dumps(log_entry)}")
# 使用例
def secure_llama_inference(prompt: str, model, tokenizer):
# 暗号化キーを環境変数から取得(本番環境)
encryption_key = Fernet.generate_key()
security_filter = SecurityFilter(encryption_key)
# プロンプトのサニタイズ
sanitized_prompt, replacement_map = security_filter.sanitize_prompt(prompt)
# セキュリティイベントのログ記録
if replacement_map:
security_filter.log_security_event(
"sensitive_data_detected",
f"Found {len(replacement_map)} sensitive data items"
)
# Llamaモデルでの推論実行
inputs = tokenizer.encode(sanitized_prompt, return_tensors="pt")
outputs = model.generate(inputs, max_length=500, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# レスポンスの機密データ復元(実際には非表示化)
secure_response = security_filter.restore_sensitive_data(response, replacement_map)
return secure_responseコンプライアンスとガバナンス
企業がLlama 3.2を導入する際は、業界固有の規制要件への準拠が必要です。GDPR、HIPAA、SOX法などの規制に対応するため、適切なガバナンス体制の構築が不可欠です。
コンプライアンスチェックリスト
☑ データ処理の透明性確保とログ記録
☑ 利用者同意の適切な取得と管理
☐ AI意思決定の説明可能性の実装
☐ 定期的な監査とレポート作成体制
☐ インシデント対応プロセスの整備
人材育成と組織変革
課題 04
既存スタッフのスキルギャップ
AI技術の急速な進歩により、既存の開発チームがLlama 3.2を効果的に活用するためのスキルが不足している場合があります。また、従来のワークフローとの統合も課題となります。
解決策
段階的な研修プログラム、ハンズオンワークショップ、メンター制度により、チーム全体のAIリテラシーを向上。外部エキスパートとの協力も効果的です。
製造業大手のF社では、全社的なAI導入プログラムの一環として、以下の人材育成戦略を実施しました:
Phase 1(1-2ヶ月)
基礎知識の習得
全従業員を対象としたAI基礎講座、Llama 3.2の概要理解、プロンプトエンジニアリングの基本を学習
Phase 2(2-3ヶ月)
実践的な実装訓練
開発チーム向けの技術研修、実際のプロジェクトでの試行、パフォーマンス最適化手法の習得
Phase 3(継続)
継続的な改善と専門化
社内エキスパート育成、最新技術のキャッチアップ、他部門への知識共有体制の構築
2026年のAI開発トレンドと未来展望
Llama 3.2の成功は、オープンソースAIの新時代を切り開きます。2026年以降、AI開発はより民主化され、イノベーションの速度が加速することが予想されます。
2026年現在、Llama 3.2を起点として、AI開発の風景は劇的に変化しています。オープンソースAIの台頭により、従来の巨大テック企業の独占的地位に変化が生じ、より多様な企業がAI分野に参入しています。
市場動向と競争環境の変化
市場調査会社Gartnerの最新レポートによると、2026年において企業のAI導入の65%がオープンソースモデルベースとなっており、これは2024年の23%から大幅な増加を示しています。この変化の主要因がLlama 3.2の影響です。
2026年のAI市場セグメント
オープンソースAI — 市場シェア65%(前年比+180%)
プロプライエタリAPI — 市場シェア25%(前年比-40%)
ハイブリッド利用 — 市場シェア8%(新規カテゴリ)
その他 — 市場シェア2%
技術進歩の加速
Llama 3.2の成功により、競合他社も次々とオープンソースモデルをリリースしています。Google の Gemma 2.5、Anthropic の Claude OSS、さらには新興企業からも革新的なモデルが登場し、AI技術の進歩速度が劇的に加速しています。
注目すべき技術トレンド
マルチモーダル統合の深化 — 音声、画像、テキストの完全統合
リアルタイム学習 — 推論中の継続学習機能
エッジAIの普及 — スマートフォンでのLLM実行
専門分野特化 — 医療、法務、金融向けカスタムモデル
規制環境の整備
AI技術の急速な普及に伴い、各国政府も規制フレームワークの整備を加速しています。特にオープンソースAIに関しては、新たな議論が活発化しています。
注意
EU AI Actの改正版が2026年後半に施行予定です。オープンソースAIの利用においても、新たなコンプライアンス要件が追加される可能性があります。
今後の発展予測
業界エキスパートへのインタビューと市場分析から、以下の発展が予測されます:
2027年までの予測
• パラメータ数1兆以上のオープンソースモデルが登場
• 推論コストがさらに90%削減
• 専門分野特化型モデルが主流化
• エッジデバイスでの完全実行が可能に
2030年までの長期展望
• AGI(汎用人工知能)への重要な進歩
• AI開発の完全民主化
• 新たなビジネスモデルの確立
• 社会インフラとの深度統合
参考リンク
最後までお読みいただきありがとうございます
Meta Llama 3.2は、オープンソースAIの新時代を切り開く革新的な技術です。適切な導入戦略により、あらゆる規模の組織が高品質なAIソリューションを実現できるようになりました。今後もAI技術の民主化が進み、イノベーションの速度はさらに加速していくでしょう。
ご質問があればコメントでどうぞ。