
要約
MLOpsツール徹底比較 2026: Kubeflow, MLflow, Vertex AIの選び方と実践
AIモデルのデプロイ、監視、管理を効率化するMLOpsの主要ツール、Kubeflow, MLflow, Vertex AIを徹底比較。
Keywords: Kubeflow, MLflow, Vertex AI
目次
1. MLOpsとは? AIモデル運用における重要性
2. 主要MLOpsツール概要: Kubeflow, MLflow, Vertex AI
3. 各ツールの詳細分析と実践
3.1. Kubeflow: KubernetesネイティブなMLプラットフォーム
3.2. MLflow: 機械学習ライフサイクル管理
3.3. Vertex AI: Google Cloudの統合MLプラットフォーム
4. MLOpsツール徹底比較 2026
5. 適切なツールの選び方と導入ガイド
6. 2026年のMLOpsトレンドと将来展望
7. よくある質問 (FAQ)
8. まとめ
背景
1. MLOpsとは? AIモデル運用における重要性
2026年現在、AI技術はビジネスのあらゆる側面に深く浸透し、その活用はもはや競争優位性を確立するための必須条件となっています。しかし、AIモデルの開発は、データ収集からモデル学習、評価、デプロイ、そして運用後の監視と再学習に至るまで、非常に複雑なライフサイクルを持っています。この複雑なプロセスを効率的かつ継続的に管理するためのアプローチが、まさに「MLOps(Machine Learning Operations)」です。
MLOpsは、DevOpsの原則を機械学習ワークフローに適用したもので、開発(Dev)、運用(Ops)、そして機械学習(ML)の各フェーズを統合し、自動化と標準化を通じてAIモデルの信頼性、スケーラビリティ、再現性を向上させることを目指します。特に、本記事で徹底比較するKubeflow、MLflow、そしてVertex AIといった主要なMLOpsツールは、この目標を達成するための強力な基盤を提供します。これらのツールを適切に選択し、実践的に導入することは、AIプロジェクトの成功に不可欠です。
従来のソフトウェア開発では、コードのデプロイ後にバグが見つかっても、修正して再デプロイすれば解決することがほとんどでした。しかし、機械学習モデルの場合、コード自体にバグがなくても、入力データの変化(データドリフト)やモデルの経年劣化(モデルドリフト)によって性能が低下することがあります。このような「サイレントエラー」は発見が難しく、ビジネスに甚大な影響を与える可能性があります。MLOpsは、このような問題を未然に防ぎ、あるいは迅速に対処するための仕組みを構築します。
例えば、あるECサイトのレコメンデーションモデルが適切に運用されていない場合、ユーザーは関連性の低い商品を勧められ、購買意欲を失う可能性があります。MLOpsを導入することで、モデルの性能指標をリアルタイムで監視し、異常を検知した際には自動的にアラートを発し、必要に応じて再学習パイプラインをトリガーするといった対応が可能になります。これにより、ビジネス価値を最大化し、AI投資のROIを高めることができるのです。
ポイント
MLOpsは、AIモデルの開発から運用までのライフサイクル全体を効率化し、モデルの信頼性、スケーラビリティ、再現性を確保するためのアプローチです。データドリフトやモデルドリフトといったAI特有の問題を解決し、ビジネス価値を最大化するために不可欠です。
概要
2. 主要MLOpsツール概要: Kubeflow, MLflow, Vertex AI
MLOpsの実現を支援するツールは数多く存在しますが、特に主要なものとしてKubeflow、MLflow、そしてVertex AIが挙げられます。これらはそれぞれ異なる設計思想と強みを持っており、プロジェクトの規模、チームの技術スタック、インフラストラクチャの選択によって最適なツールは異なります。
Kubeflow: KubernetesネイティブなMLプラットフォーム
概要 — Kubernetes上で機械学習ワークフローをデプロイ、管理、スケーリングするためのオープンソースプラットフォーム。コンテナ化されたコンポーネントで構成され、高い柔軟性と拡張性を提供します。
主な強み — クラウドベンダーに依存しない移植性、複雑なパイプライン構築能力、Kubernetesエコシステムとの深い統合。
MLflow: 機械学習ライフサイクル管理
概要 — 機械学習のライフサイクル(実験管理、再現可能なコードパッケージ化、モデルデプロイ、モデルレジストリ)を管理するためのオープンソースプラットフォーム。特定のMLフレームワークやインフラに依存しません。
主な強み — 軽量で導入しやすい、実験管理機能が充実、幅広い環境での利用が可能、モデルのバージョン管理。
Vertex AI: Google Cloudの統合MLプラットフォーム
概要 — データ準備からモデルデプロイ、監視、管理まで、機械学習の全ワークフローをカバーするGoogle Cloudのフルマネージドサービス。Googleの内部MLプラットフォーム技術を外部に提供します。
主な強み — フルマネージドで運用負荷が低い、Google Cloudエコシステムとのシームレスな統合、最先端のAI機能へのアクセス。
ポイント
これら3つのツールは、それぞれオープンソースの柔軟性、軽量なライフサイクル管理、またはフルマネージドの容易さという異なるアプローチでMLOpsの課題解決を目指しています。プロジェクトの要件に応じて最適なツールを選ぶことが重要です。
詳細分析
3. 各ツールの詳細分析と実践
3.1. Kubeflow: KubernetesネイティブなMLプラットフォーム
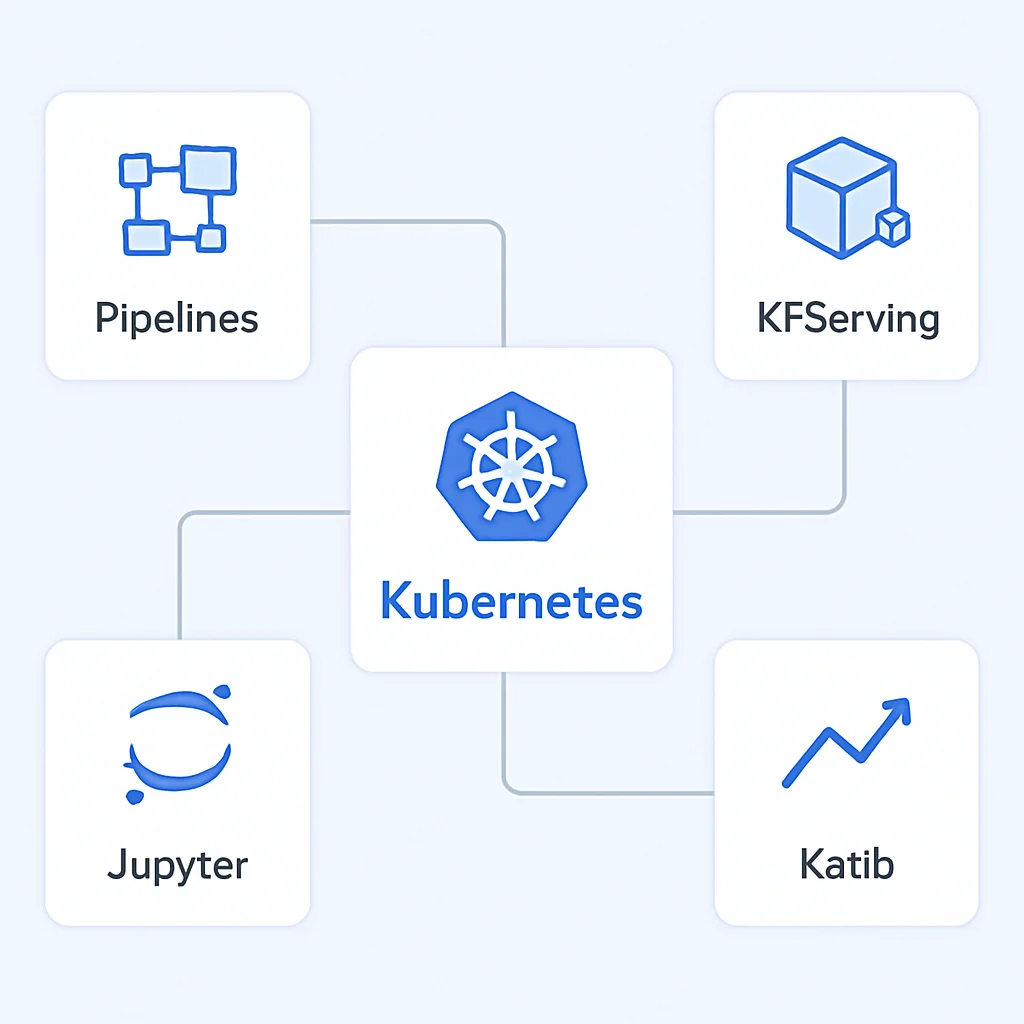
Kubeflowは、Kubernetes上で機械学習ワークフローを効率的にデプロイ、管理、スケーリングするために設計されたオープンソースプロジェクトです。その核心は、機械学習の各ステップ(データ処理、モデルトレーニング、ハイパーパラメータチューニング、モデルサービングなど)をKubernetesコンテナとして実行し、それらをパイプラインとしてオーケストレーションする能力にあります。これにより、インフラの抽象化とリソース管理の効率化を実現します。
主要コンポーネント:
• Kubeflow Pipelines: 複雑なMLワークフローをコンテナベースのパイプラインとして定義し、実行、監視するためのプラットフォーム。Argo Workflowsを基盤としています。
• KFServing (KServe): 機械学習モデルをKubernetes上でスケーラブルかつ高性能にデプロイするためのフレームワーク。IstioやKnativeと連携し、自動スケーリングやトラフィックルーティングをサポートします。
• Jupyter Notebooks: 開発者がKubernetesクラスタ上で直接Jupyter Notebook環境をプロビジョニングし、モデル開発を行うための機能。
• Katib: ハイパーパラメータチューニングとニューラルアーキテクチャ探索(NAS)のためのオープンソースシステム。
Kubeflowの最大のメリットは、その高い柔軟性とベンダーロックインからの解放です。オンプレミス、任意のクラウドプロバイダー、またはハイブリッド環境でKubernetesが動作する場所であればどこでも利用できます。しかし、その分、Kubernetesに関する深い知識と運用スキルが求められ、初期セットアップや管理の複雑さがデメリットとなることがあります。
メリット
✓ 高い柔軟性と移植性: Kubernetesが動作するあらゆる環境で利用可能。
✓ スケーラビリティ: Kubernetesの強力なリソース管理とスケーリング機能を活用。
✓ 包括的な機能: パイプライン、サービング、ノートブック、ハイパーパラメータチューニングなど、MLOpsの全フェーズをカバー。
デメリット
✗ 高い学習コスト: KubernetesとMLOpsに関する深い知識が必要。
✗ 複雑なセットアップと運用: 多くのコンポーネントを手動で管理する必要がある。
✗ リソース消費: フルスタックで導入すると、かなりのKubernetesリソースを消費する。
コード解説
以下は、Kubeflow Pipelinesで簡単な機械学習パイプラインを定義するPythonコードの例です。データ処理、トレーニング、モデル評価の3つのステップで構成されています。Kubeflow SDKを使用して、各ステップをコンポーネントとして定義し、それらを順序付けてパイプラインを構築します。
import kfp
from kfp import dsl
# コンポーネントの定義
# 通常は個別のPythonファイルとして定義し、kfp.components.create_component_from_funcでロード
def data_preprocessing(input_data_path: str, output_data_path: dsl.OutputPath(str)):
"""
データの前処理を行うコンポーネント。
"""
print(f"データ {input_data_path} を前処理中...")
# 実際の前処理ロジック
preprocessed_data = "preprocessed_data.csv" # 仮の出力
with open(output_data_path, 'w') as f:
f.write(preprocessed_data)
print(f"前処理済みデータを {output_data_path} に保存しました。")
def model_training(training_data_path: str, model_output_path: dsl.OutputPath(str)):
"""
モデルのトレーニングを行うコンポーネント。
"""
print(f"データ {training_data_path} でモデルをトレーニング中...")
# 実際のモデルトレーニングロジック
trained_model = "model.pkl" # 仮の出力
with open(model_output_path, 'w') as f:
f.write(trained_model)
print(f"トレーニング済みモデルを {model_output_path} に保存しました。")
def model_evaluation(model_path: str, evaluation_report_path: dsl.OutputPath(str)):
"""
モデルの評価を行うコンポーネント。
"""
print(f"モデル {model_path} を評価中...")
# 実際のモデル評価ロジック
evaluation_report = "accuracy: 0.95" # 仮の出力
with open(evaluation_report_path, 'w') as f:
f.write(evaluation_report)
print(f"評価レポートを {evaluation_report_path} に保存しました。")
# コンポーネントの作成
preprocess_op = kfp.components.create_component_from_func(
data_preprocessing,
base_image='python:3.9-slim', # コンポーネントが実行されるDockerイメージ
packages_to_install=['pandas', 'scikit-learn'] # 必要なライブラリ
)
train_op = kfp.components.create_component_from_func(
model_training,
base_image='python:3.9-slim',
packages_to_install=['tensorflow', 'scikit-learn']
)
evaluate_op = kfp.components.create_component_from_func(
model_evaluation,
base_image='python:3.9-slim',
packages_to_install=['scikit-learn']
)
# パイプラインの定義
@dsl.pipeline(
name='Simple ML Pipeline',
description='A simple machine learning pipeline for demonstration.'
)
def simple_ml_pipeline(
input_data: str = 'gs://my-bucket/data.csv' # デフォルトの入力データパス
):
# データ前処理ステップ
preprocess_task = preprocess_op(input_data_path=input_data)
# モデルトレーニングステップ (前処理の出力に依存)
train_task = train_op(training_data_path=preprocess_task.outputs['output_data_path'])
# モデル評価ステップ (トレーニングの出力に依存)
evaluate_task = evaluate_op(model_path=train_task.outputs['model_output_path'])
# パイプライン実行後のログ出力など
print_evaluation_result = dsl.ContainerOp(
name='print_evaluation_result',
image='ubuntu:latest',
command=['sh', '-c'],
arguments=['echo "評価結果: $(cat {})"'.format(evaluate_task.outputs['evaluation_report_path'])]
)
if __name__ == '__main__':
# Kubeflowクライアントの初期化 (Kubeflow環境で実行する場合)
# kfp.Client()
# パイプラインのコンパイルとアップロード (通常はCLIまたはSDKで)
# kfp.compiler.Compiler().compile(simple_ml_pipeline, 'simple_ml_pipeline.yaml')
# print("Pipeline compiled to simple_ml_pipeline.yaml")
pass
問題 01
Kubeflowの複雑なセットアップと運用
Kubeflowは非常に強力ですが、多くのコンポーネントから構成されており、Kubernetesクラスタの構築、Kubeflow本体のインストール、各コンポーネントの設定、そして継続的なメンテナンスには専門的な知識と時間が必要です。特に小規模チームやKubernetesの経験が浅いチームにとっては大きな障壁となり得ます。
解決策 — マネージドKubernetesサービスの活用と段階的導入
Google Kubernetes Engine (GKE), Amazon EKS, Azure AKSなどのマネージドKubernetesサービスを利用することで、クラスタの運用負荷を大幅に軽減できます。また、Kubeflowの全コンポーネントを一度に導入するのではなく、Kubeflow PipelinesやJupyter Notebooksなど、必要最小限の機能から段階的に導入し、運用しながら習熟していくアプローチが有効です。専門のコンサルティングサービスを活用することも一考です。
ポイント
Kubeflowは、Kubernetesの強力なスケーラビリティと柔軟性を活用し、MLワークフローをコンテナベースでオーケストレーションします。導入にはKubernetesの専門知識が求められますが、マネージドサービスや段階的導入によりその障壁を低減できます。
3.2. MLflow: 機械学習ライフサイクル管理
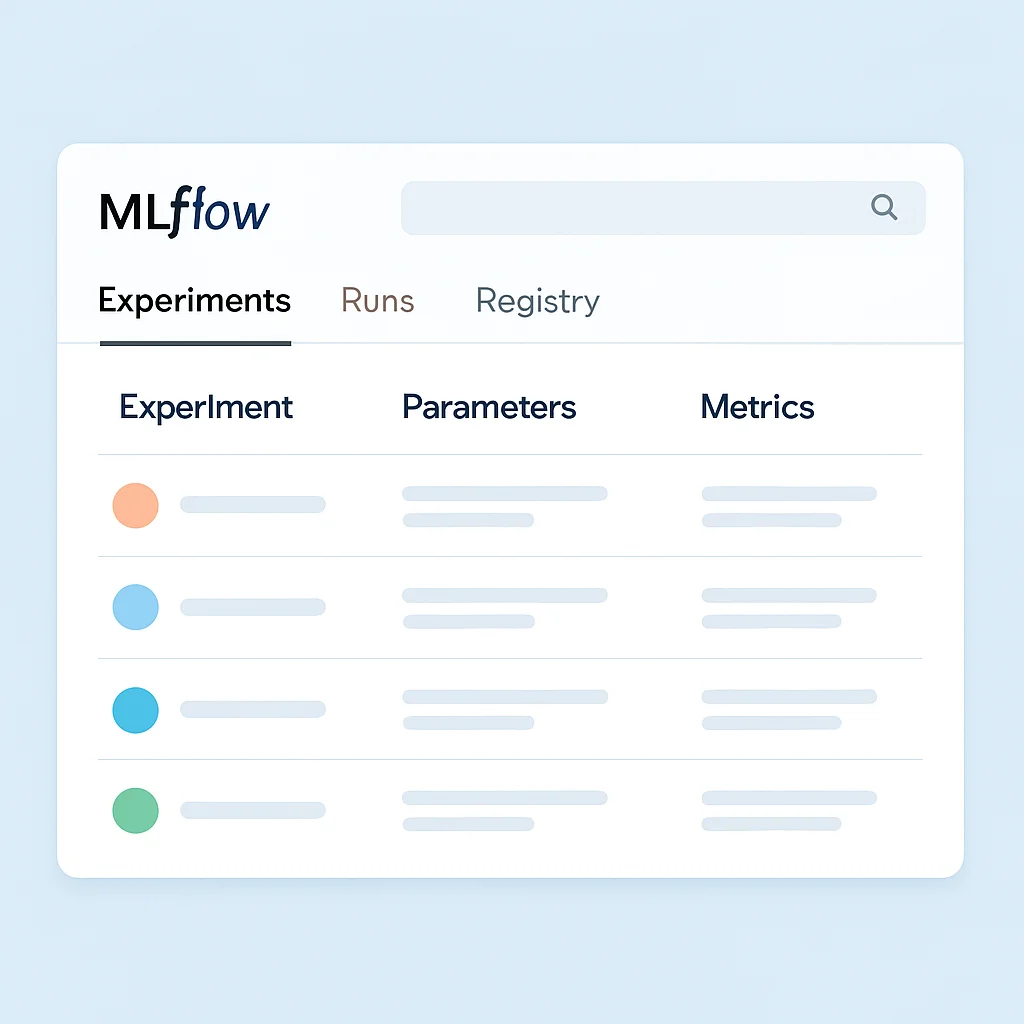
MLflowは、機械学習のライフサイクル全体を管理するためのオープンソースプラットフォームです。特定のMLフレームワークやクラウドプロバイダーに依存しない設計が特徴で、実験管理、再現可能なパッケージ化、モデルデプロイ、モデルレジストリといった主要な機能を提供します。その軽量さと使いやすさから、多くのデータサイエンティストやMLエンジニアに支持されています。
主要コンポーネント:
• MLflow Tracking: 実験のパラメータ、メトリクス、アーティファクト(モデルファイルなど)を記録し、比較するためのAPIとUIを提供します。これにより、どの実験が最良の結果をもたらしたかを簡単に追跡できます。
• MLflow Projects: MLコードを再現可能な形式でパッケージ化するための標準フォーマットを提供します。これにより、他のデータサイエンティストが同じ環境でコードを実行し、結果を再現することが容易になります。
• MLflow Models: さまざまなMLフレームワーク(TensorFlow, PyTorch, scikit-learnなど)で学習されたモデルを、多様なデプロイツール(REST API, Apache Sparkなど)で利用できる標準フォーマットでパッケージ化します。
• MLflow Model Registry: モデルのライフサイクル全体(ステージング、プロダクション、アーカイブなど)を一元的に管理し、バージョン管理やモデルの承認ワークフローをサポートします。
MLflowは、特に実験管理とモデルのバージョン管理において強力な機能を発揮します。既存のMLワークフローに容易に統合でき、小規模から中規模のプロジェクトで迅速にMLOpsの恩恵を受けたい場合に最適です。Databricksが開発を主導しており、Databricksプラットフォーム上ではフルマネージドサービスとして提供されています。
メリット
✓ 軽量で導入が容易: 既存のPythonプロジェクトに数行のコードで統合可能。
✓ 優れた実験管理: パラメータ、メトリクス、アーティファクトの追跡が容易。
✓ フレームワーク非依存: TensorFlow, PyTorch, scikit-learnなど、あらゆるMLフレームワークに対応。
デメリット
✗ パイプラインオーケストレーション機能の不足: Kubeflowのような複雑なパイプライン構築には、他のツール(Airflow, Kubeflow Pipelinesなど)との連携が必要。
✗ スケーラビリティの課題: 大規模なチームや多数の実験を管理する場合、自前でのインフラ構築・運用が複雑になる可能性。
✗ モデル監視機能の不足: デプロイ後のモデル性能監視は、別途ツール(Prometheus, Grafanaなど)との連携が必要。
コード解説
以下は、MLflow Trackingを使用してシンプルなscikit-learnモデルのトレーニング実験を記録するPythonコードの例です。ハイパーパラメータ、メトリクス、モデル自体をMLflowにログとして記録します。
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.datasets import load_iris
# MLflow TrackingサーバのURIを設定 (デフォルトは 'mlruns')
# mlflow.set_tracking_uri("http://localhost:5000") # リモートサーバの場合
# 実験名を設定
mlflow.set_experiment("Iris_Classifier_Experiment")
# MLflowの実行を開始
with mlflow.start_run():
# データロード
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ハイパーパラメータ
n_estimators = 100
max_depth = 10
# ハイパーパラメータをMLflowにログ
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
# モデルトレーニング
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=42)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# メトリクス計算
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
# メトリクスをMLflowにログ
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("precision", precision)
mlflow.log_metric("recall", recall)
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
# モデルをMLflowに保存
# mlflow.sklearn.log_modelはモデルとその環境(conda.yaml)を自動で保存
mlflow.sklearn.log_model(model, "random_forest_model", registered_model_name="IrisClassifier")
print("MLflow run completed.")
print(f"Run ID: {mlflow.active_run().info.run_id}")
print("View MLflow UI by running 'mlflow ui' in your terminal.")
問題 02
大規模なチームや多数の実験におけるMLflowの運用
MLflowは個別の実験管理には非常に優れていますが、大規模なチームで共有のMLflow TrackingサーバやModel Registryを運用する場合、データベースの管理、ストレージの確保、認証・認可の設定、高可用性の担保など、インフラストラクチャの運用が複雑になります。特に、複数のプロジェクトや部署で利用する際には、これらの課題が顕著になります。
解決策 — マネージドMLflowサービスの利用またはクラウドストレージ連携
Databricksが提供するマネージドMLflowは、これらの運用課題を解決するための最も簡単な方法です。自前でホストする場合は、MLflow TrackingサーバのバックエンドデータベースとしてPostgreSQLなどのリレーショナルデータベース、アーティファクトストレージとしてAmazon S3やGoogle Cloud Storageなどのオブジェクトストレージを利用することで、スケーラビリティと信頼性を向上させることができます。また、Kubernetes上でMLflowをデプロイし、そのスケーリング機能を活用することも可能です。
ポイント
MLflowは、実験管理とモデルライフサイクル管理に特化した軽量なツールで、フレームワーク非依存性が大きな強みです。大規模な運用にはインフラの考慮が必要ですが、マネージドサービスやクラウドストレージとの連携で解決可能です。
3.3. Vertex AI: Google Cloudの統合MLプラットフォーム
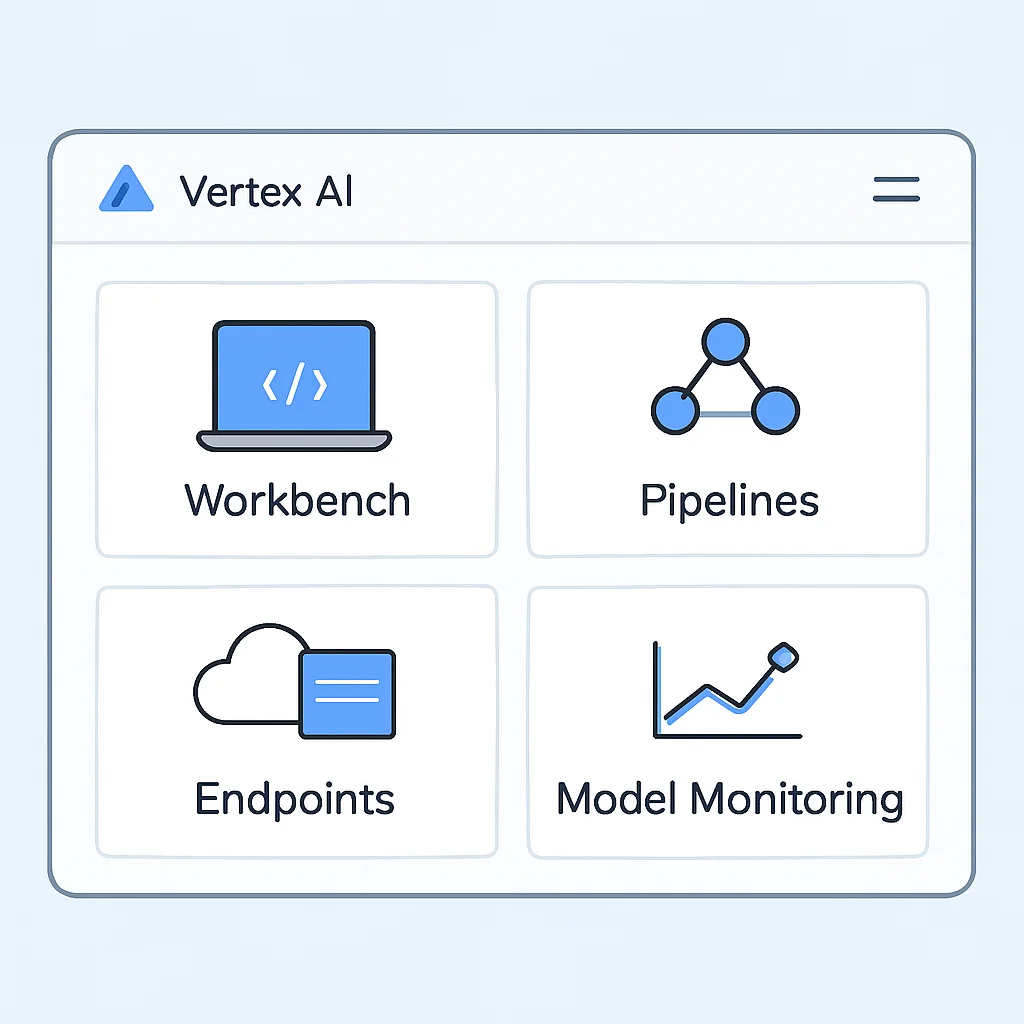
Vertex AIは、Google Cloudが提供するフルマネージドの機械学習プラットフォームです。データ準備からモデルトレーニング、デプロイ、監視、そしてMLOpsの全プロセスを単一のプラットフォームで提供することを目的としています。Googleが社内で培ってきた機械学習技術とインフラを外部ユーザーに開放する形で、非常に強力でスケーラブルな機能を提供します。
主要コンポーネントと機能:
• Vertex AI Workbench: Jupyter Notebook環境を提供するマネージドサービス。データ探索やモデル開発を効率的に行えます。
• Vertex AI Training: カスタムモデルやAutoMLモデルのトレーニングを大規模に行うためのサービス。GPUやTPUなどの強力なコンピューティングリソースを利用できます。
• Vertex AI Pipelines: TFX (TensorFlow Extended) や Kubeflow Pipelines SDK をベースに、MLワークフローをオーケストレーションするためのマネージドサービス。複雑なパイプラインも容易に構築・実行できます。
• Vertex AI Endpoints: トレーニング済みモデルをリアルタイム予測やバッチ予測のためにデプロイし、高可用性・低レイテンシーでサービングするためのサービス。自動スケーリングやモデルバージョニングもサポートします。
• Vertex AI Feature Store: 特徴量を一元的に管理し、トレーニングとサービングで一貫して利用するためのサービス。特徴量エンジニアリングの再現性と効率性を高めます。
• Vertex AI Model Monitoring: デプロイされたモデルの性能(精度、ドリフトなど)を自動で監視し、異常を検知した際にアラートを発するサービス。
Vertex AIは、Google Cloudの他のサービス(BigQuery, Cloud Storageなど)とシームレスに統合されており、データサイエンティストやMLエンジニアがインフラの管理に煩わされることなく、モデル開発に集中できる環境を提供します。特に、Google Cloudをメインのインフラとして利用している企業にとっては、非常に強力な選択肢となります。
メリット
✓ フルマネージドサービス: インフラ運用負荷が極めて低い。
✓ 統合されたプラットフォーム: MLライフサイクルの全フェーズを単一環境でカバー。
✓ Google Cloudとの深い統合: BigQuery, Cloud Storageなど、既存のGCP資産とシームレスに連携。
デメリット
✗ ベンダーロックイン: Google Cloudに依存するため、他のクラウドやオンプレミスへの移行が困難。
✗ コスト: 高度なマネージドサービスであるため、利用状況によってはコストが高くなる可能性がある。
✗ 学習コスト: Google Cloudの概念やVertex AIのAPIに慣れる必要がある。
コード解説
以下は、Vertex AI Python SDKを使用して、Google Cloud Storageに保存されたモデルをVertex AI Endpointsにデプロイする簡略化された例です。これにより、モデルをREST APIとして公開し、予測リクエストを受け付ける準備ができます。
from google.cloud import aiplatform
# プロジェクトIDとリージョンを設定
PROJECT_ID = "your-gcp-project-id"
REGION = "us-central1" # またはお使いのリージョン
# Vertex AIクライアントを初期化
aiplatform.init(project=PROJECT_ID, location=REGION)
# モデルの表示名とGCS上のモデルのURI
MODEL_DISPLAY_NAME = "my-sklearn-model-2026"
MODEL_GCS_URI = "gs://your-bucket/path/to/model_dir" # TensorFlow SavedModelまたはScikit-learnモデルのディレクトリ
# モデルをVertex AIにアップロード
# この例では、Scikit-learnモデルを想定 (GCS URIはモデルディレクトリを指す)
# framework='scikit-learn' を指定することで、適切なコンテナイメージが自動的に選択されます
uploaded_model = aiplatform.Model.upload(
display_name=MODEL_DISPLAY_NAME,
artifact_uri=MODEL_GCS_URI,
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", # またはカスタムコンテナ
labels={"framework": "sklearn", "version": "1.0"}
)
uploaded_model.wait() # アップロード完了を待機
print(f"Model uploaded. Resource name: {uploaded_model.resource_name}")
# エンドポイントの作成
ENDPOINT_DISPLAY_NAME = "my-sklearn-endpoint-2026"
endpoint = aiplatform.Endpoint.create(display_name=ENDPOINT_DISPLAY_NAME)
print(f"Endpoint created. Resource name: {endpoint.resource_name}")
# モデルをエンドポイントにデプロイ
# machine_typeやmin_replica_count, max_replica_countでリソースとスケーリングを制御
traffic_split = {"0": 100} # デプロイされたモデルのトラフィックを100%に設定
deployed_model = endpoint.deploy(
model=uploaded_model,
deployed_model_display_name=f"{MODEL_DISPLAY_NAME}_deployed",
machine_type="n1-standard-2", # 予測に使用するVMのタイプ
min_replica_count=1,
max_replica_count=2,
traffic_split=traffic_split
)
deployed_model.wait() # デプロイ完了を待機
print(f"Model deployed to endpoint: {endpoint.resource_name}")
print(f"Deployed model ID: {deployed_model.id}")
# 予測リクエストの例 (デプロイ後に実行)
# from google.cloud.aiplatform.gapic.schema import predict_pb2
# import json
# instance = predict_pb2.Instance(
# struct_value=json_format.ParseDict(
# {"feature1": 1.0, "feature2": 2.0, "feature3": 3.0}, Value()
# )
# )
# instances = [instance]
# prediction = endpoint.predict(instances=instances)
# print(prediction)
問題 03
Vertex AIにおけるコスト管理とベンダーロックイン
Vertex AIは強力ですが、その高機能性とフルマネージドの恩恵は、時に予期せぬコスト増大につながる可能性があります。特に、多くのリソースを消費するトレーニングジョブや、24時間稼働するEndpointなどは、継続的にコストを発生させます。また、Google Cloudに深く依存するため、将来的に他のクラウドプロバイダーへの移行を検討する際に大きな障壁となる可能性があります。
解決策 — コスト監視とハイブリッド戦略
Google Cloudの課金アラートやコスト管理ツールを積極的に活用し、予算超過を防ぐための仕組みを構築することが重要です。また、Vertex AIの機能をすべて利用するのではなく、特定のワークロード(例えば、モデルトレーニングはVertex AI、実験管理はMLflow)で他のツールと組み合わせるハイブリッド戦略も有効です。これにより、ベンダーロックインのリスクを分散し、コスト効率の良い運用を目指せます。
ポイント
Vertex AIは、Google Cloud上でMLOpsを統合的に実現するフルマネージドプラットフォームであり、高い生産性とスケーラビリティを提供します。しかし、コスト管理とベンダーロックインへの注意が必要であり、ハイブリッド戦略も考慮すべきです。
比較分析
4. MLOpsツール徹底比較 2026
これまで個別に見てきたKubeflow、MLflow、Vertex AIですが、ここではそれらを包括的に比較し、それぞれの特性を明確にします。2026年時点での機能、エコシステム、運用モデル、そしてコスト効率の観点から、どのようなプロジェクトにどのツールが最適なのかを深く掘り下げていきます。
比較ポイント:
• 運用モデル: オープンソース(セルフホスト)か、マネージドサービスか。
• 機能範囲: MLOpsライフサイクルのどのフェーズをカバーしているか。
• インフラ依存性: 特定のクラウドプロバイダーに依存するか、汎用性が高いか。
• 学習曲線と複雑性: 導入・運用に必要な技術的スキルレベル。
• コストモデル: 初期費用、運用費用、スケーリングに伴う費用。
以下の表は、これらの主要なMLOpsツールの特性を分かりやすくまとめたものです。
| 項目 | Kubeflow | MLflow | Vertex AI |
|---|---|---|---|
| 運用モデル | オープンソース (セルフホスト) | オープンソース (セルフホスト/マネージド) | フルマネージドサービス |
| 主要機能 | パイプラインオーケストレーション、モデルサービング、ノートブック、ハイパーパラメータチューニング | 実験管理、モデルパッケージング、モデルレジストリ、モデルデプロイ | データ準備、トレーニング、パイプライン、エンドポイント、フィーチャーストア、モデル監視 |
| インフラ依存性 | Kubernetes (クラウド非依存) | フレームワーク・クラウド非依存 | Google Cloudに完全に依存 |
| 学習曲線/複雑性 | 高 (Kubernetes知識必須) | 中 (比較的容易) | 中〜高 (GCPエコシステム知識必要) |
| スケーラビリティ | Kubernetesベースで非常に高い | 自前運用の場合、インフラ設計に依存。マネージド版は高い | Google Cloudインフラで非常に高い |
| コストモデル | インフラ費用 + 運用人件費 | インフラ費用 (自前) またはサービス利用料 (マネージド) | 従量課金制 (利用リソースに基づく) |
| 理想的なユースケース | 複雑なMLOpsパイプライン、ベンダーロックイン回避、Kubernetes熟練チーム | 実験管理重視、既存ワークフローへの統合、軽量なMLOps導入 | GCPユーザー、運用負荷最小化、フルスタックMLOps、最先端機能利用 |
この比較表からわかるように、各ツールは異なる強みと弱みを持っています。Kubeflowは、Kubernetesの柔軟性とスケーラビリティを最大限に活用したい、そして自社でインフラを完全にコントロールしたい企業に適しています。高い技術力が求められますが、その見返りとしてベンダーロックインを回避できるという大きなメリットがあります。
MLflowは、特に実験管理とモデルのバージョン管理に焦点を当てており、既存のML開発ワークフローに比較的容易に導入できます。フルスタックのMLOpsプラットフォームとまでは言えませんが、パイプラインオーケストレーションやモデル監視を他のツールと組み合わせることで、非常に効果的なMLOps環境を構築できます。小規模から中規模のチーム、または特定のMLOpsフェーズに課題を抱えているチームに最適です。
Vertex AIは、Google Cloudユーザーにとって最も魅力的な選択肢です。フルマネージドであるため運用負荷が極めて低く、データ準備からデプロイ、監視までMLOpsの全プロセスを統合されたプラットフォームで実現できます。最新のAI技術やGoogleの強力なインフラを最大限に活用したい場合に最適ですが、その反面、ベンダーロックインのリスクとコスト管理が重要な課題となります。
ポイント
KubeflowはKubernetesの柔軟性、MLflowは実験管理の容易さ、Vertex AIはGCPの統合されたマネージドサービスがそれぞれの最大の特徴です。プロジェクトの規模、チームの技術力、インフラ戦略に応じて最適なツールは異なります。
導入ガイド
5. 適切なツールの選び方と導入ガイド
ここまで各ツールの詳細と徹底比較を行ってきましたが、最終的にどのツールを選ぶべきか、具体的な判断基準と導入のステップについて解説します。プロジェクトの成功は、適切なツール選定にかかっています。
ツールの選び方: 意思決定のフレームワーク
以下の質問に答えることで、最適なMLOpsツールへの道筋が見えてきます。
MLOpsツール選定チェックリスト
☑ 既存のインフラストラクチャは? — 主にGoogle Cloudを利用しているか? Kubernetesクラスタを運用しているか?
☑ チームの技術スキルは? — Kubernetes、クラウドサービス、MLOpsの専門知識を持つメンバーがいるか?
☑ プロジェクトの規模と複雑性は? — 小規模なPOCか、大規模な本番運用か? パイプラインは複雑か?
☑ 運用負荷への許容度は? — マネージドサービスによる低負荷を重視するか、自前運用による完全なコントロールを重視するか?
☑ ベンダーロックインへの懸念は? — 特定のクラウドベンダーへの依存を避けたいか?
☑ 予算は? — 初期投資、運用コスト、スケーリングコストを考慮した予算枠はどれくらいか?
具体的な推奨:
• Kubeflowが適している場合:
Kubernetesに関する深い知識を持つ専門チームがおり、複雑な機械学習パイプラインをエンドツーエンドで構築したい場合。ベンダーロックインを避け、インフラを完全にコントロールしたい大規模な企業や、マルチクラウド戦略を採用している場合に最適です。
• MLflowが適している場合:
主に実験管理とモデルのバージョン管理に焦点を当てたい場合。既存のML開発ワークフローに比較的容易にMLOpsの要素を取り入れたい小規模〜中規模のチームや、特定のクラウドプロバイダーに依存したくない場合に推奨されます。Databricksユーザーであれば、マネージドMLflowが強力な選択肢となります。
• Vertex AIが適している場合:
既にGoogle Cloudを主要なクラウ