
要約
LangChainで始めるAIエージェント開発入門 2026: LLMを活用した自律システムの作り方
LangChainを用いてAIエージェントを開発するための基礎から実践までを、2026年最新の視点から詳細に解説します。
Keywords: LangChain, AIエージェント, LLM活用
目次
1. AIエージェント開発の夜明け:なぜ今LangChainなのか?
2. LangChainで構築するAIエージェントの基本構造
3. 高度なAIエージェントの設計と実装戦略
4. AIエージェント開発における主要な課題とその解決策
5. 実践!LangChainによるAIエージェントの構築事例
6. AIエージェントの未来:2026年以降の展望
7. よくある質問 (FAQ)
1. AIエージェント開発の夜明け:なぜ今LangChainなのか?
生成AIの進化は目覚ましく、特に大規模言語モデル(LLM)は私たちの仕事や生活に革命をもたらし始めています。しかし、LLM単体では、ユーザーの指示を理解し、その場で情報を生成する以上の複雑なタスク、例えば外部ツールを呼び出したり、過去の会話履歴を記憶したり、自律的に意思決定を行うことは困難です。ここで登場するのが「AIエージェント」です。AIエージェントは、LLMを「脳」として活用し、ツールを使いこなし、記憶を持ち、計画を立てて実行することで、人間のように自律的に目標達成を目指すシステムを指します。
2026年現在、AIエージェントの概念は単なる研究テーマに留まらず、ビジネスの最前線で具体的な価値を生み出し始めています。顧客サポートの自動化、データ分析の効率化、パーソナライズされたコンテンツ生成、さらには複雑なソフトウェア開発の支援まで、その応用範囲は日々拡大しています。市場調査会社ガートナーは、2025年までにAIエージェントが企業のデジタル変革において不可欠な要素となると予測しており、関連市場は年率30%以上の成長を続けると見られています。
このような背景の中、AIエージェント開発のフレームワークとして急速にその地位を確立しているのが「LangChain」です。LangChainは、LLMをベースとしたアプリケーション開発を簡素化し、エージェントの構築に必要な様々なコンポーネント(LLMの呼び出し、プロンプト管理、外部ツールとの連携、記憶管理など)をモジュール化して提供します。PythonとJavaScript/TypeScriptに対応しており、開発者はこれらのコンポーネントを組み合わせて、複雑なAIエージェントを効率的に構築できます。
LangChainがこれほどまでに注目される理由は、その柔軟性と拡張性にあります。多様なLLMプロバイダー(OpenAI, Google, Anthropicなど)に対応し、Web検索、データベース操作、API呼び出しといった様々な外部ツールを簡単に組み込めます。また、エージェントの思考プロセスを可視化・デバッグするための機能も充実しており、開発者はより堅牢で信頼性の高いエージェントを構築することが可能です。本記事では、LangChainを使いこなすことで、いかにしてLLMの潜在能力を最大限に引き出し、真に自律的なAIシステムを構築できるかを、具体的なコード例を交えながら深掘りしていきます。
ポイント
AIエージェントはLLMの能力を拡張し、外部ツール連携、記憶、自律的意思決定を可能にするシステムです。LangChainは、このAIエージェント開発を効率化するための強力なフレームワークであり、多様なLLMやツールとの連携を容易にします。
2. LangChainで構築するAIエージェントの基本構造
LangChainにおけるAIエージェントは、いくつかの主要なコンポーネントが連携して動作します。これらのコンポーネントを理解することが、効果的なエージェントを構築するための第一歩です。
AIエージェントの主要コンポーネント
AIエージェントは、主に以下の要素で構成されます。
LangChainエージェントの構成要素
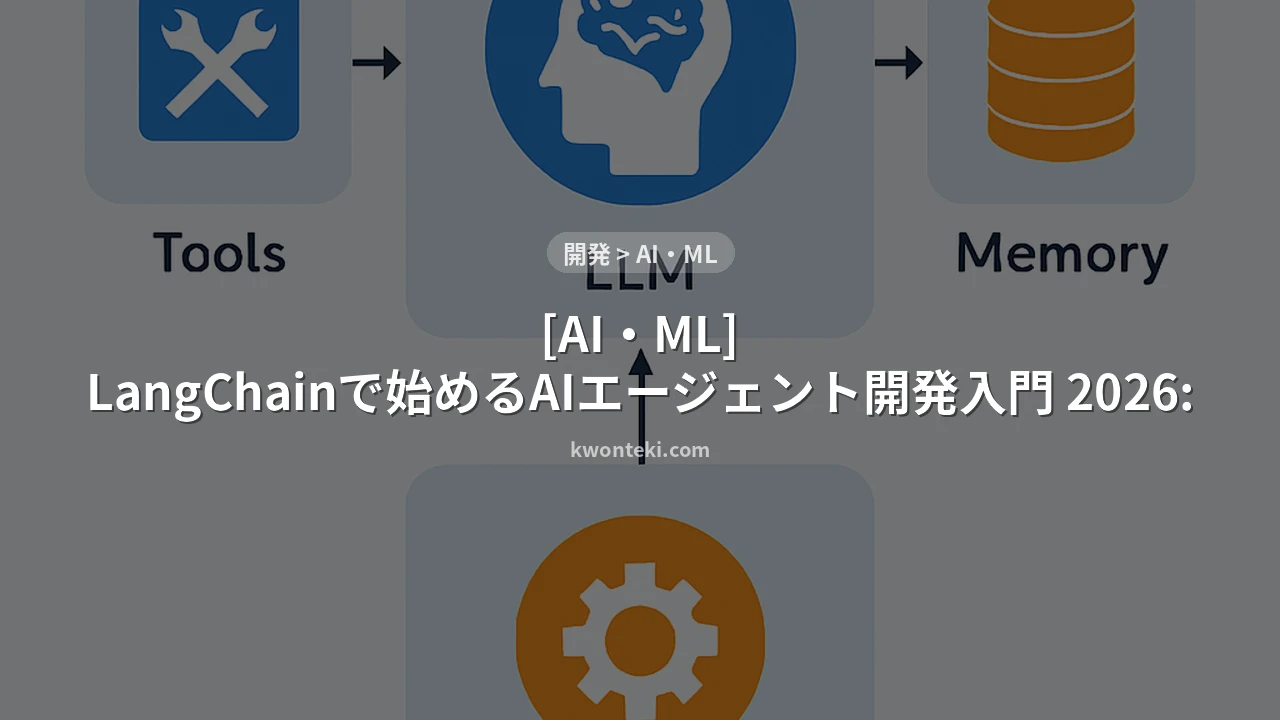
1. LLM (Large Language Model) — エージェントの「脳」として機能し、ユーザーの指示を理解し、次の行動を決定します。
2. Tools (ツール) — エージェントが外部とやり取りするための機能です。Web検索、電卓、API呼び出し、データベースクエリなどが含まれます。
3. Memory (記憶) — エージェントが過去の会話履歴や取得した情報を保持し、長期的なコンテキストを維持するために使用します。
4. Agent Executor (エージェント実行器) — LLMからの指示に基づき、どのツールを使用し、どのような情報を記憶し、次に何をするかを決定し、実行するロジックです。
Toolsの活用:エージェントの能力を無限に拡張する
ToolsはAIエージェントが外部の世界とインタラクトするための「手足」です。LLMはテキスト生成能力に優れていますが、リアルタイムのデータ取得や複雑な計算、特定のAPI操作は苦手です。Toolsを組み込むことで、これらの弱点を補い、エージェントの能力を飛躍的に向上させることができます。
LangChainでは、以下のような多様なToolsが標準で提供されています。
- SerpAPIWrapper / DuckDuckGoSearchRun: Web検索を行い、最新の情報を取得します。
- LLMMathChain: 数学的な計算を実行します。
- PythonREPLTool: Pythonコードを実行し、データ操作や複雑なロジックを処理します。
- Custom Tools: 独自のAPIやデータベース操作など、特定のビジネスロジックに対応するカスタムツールを簡単に作成できます。
例えば、ユーザーが「〇〇の最新の株価を教えて」と尋ねた場合、エージェントはWeb検索ツールを使ってリアルタイムの株価データを取得し、その結果をLLMに渡して自然な言葉で回答を生成するといった一連の動作が可能になります。
Memoryの種類と役割:コンテキストの維持
LLMは基本的にステートレスであり、個々のプロンプトは独立して処理されます。しかし、会話型AIエージェントでは、過去のやり取りを記憶し、それを現在のコンテキストとして利用することが不可欠です。LangChainのMemoryモジュールは、この記憶管理を容易にします。
- ConversationBufferMemory: 最もシンプルな記憶タイプで、過去の会話履歴をそのまま保持します。
- ConversationSummaryMemory: 過去の会話を要約し、記憶のサイズを管理します。これにより、長い会話でもLLMのトークン制限を超えにくくなります。
- ConversationBufferWindowMemory: 直近N件の会話のみを記憶します。
- VectorStoreRetrieverMemory: 過去の会話から関連性の高い情報をベクトルデータベースから検索して取得し、LLMに渡します。長期記憶や大量の情報を扱う場合に特に有効です。
適切なMemory戦略を選択することで、エージェントはより一貫性のある、パーソナライズされた対話を提供できるようになります。
Agent Typesの比較:思考プロセスの選択
LangChainには、エージェントが思考し、行動を決定するための複数の「Agent Types」が存在します。これらは、LLMがどのようにプロンプトを解釈し、ツールを使用し、最終的な回答を生成するかを定義します。
- zero-shot-react-description: ReAct (Reasoning and Acting) フレームワークに基づいています。LLMは思考(Thought)と行動(Action)を交互に繰り返し、タスクを解決します。汎用性が高く、様々なタスクに適しています。
- OpenAI Functions: OpenAIのFunction Calling機能を活用します。LLMが、利用可能なツールとそのスキーマに基づいて、適切なツール呼び出しを直接生成します。構造化されたツール呼び出しに非常に優れており、安定性が高いのが特徴です。
- conversational-react-description: ReActエージェントに会話履歴の記憶機能を追加したものです。過去の会話を考慮した上で意思決定を行います。
タスクの複雑さ、LLMの特性、そして必要な制御のレベルに応じて、最適なAgent Typeを選択することが重要です。2026年現在、OpenAI Functionsは特にその堅牢性から多くの開発者に採用されています。
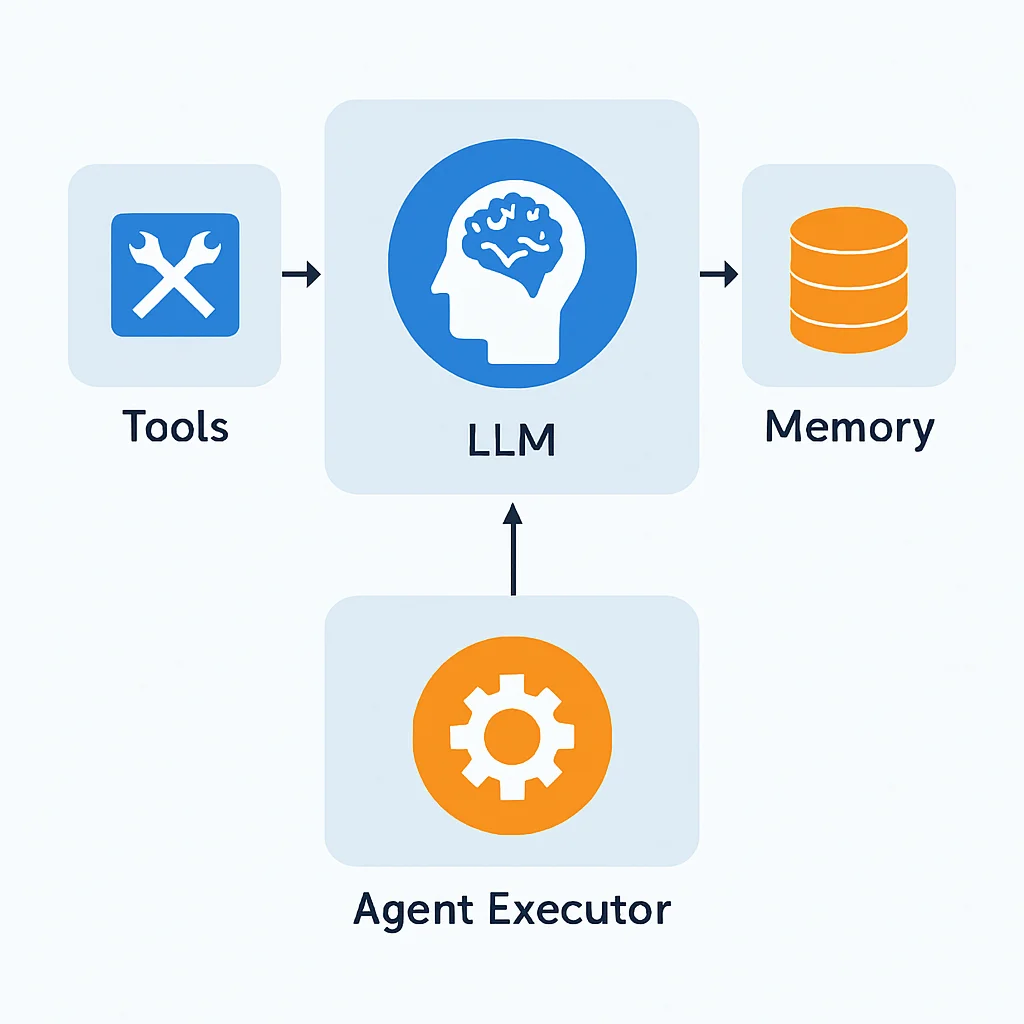
上記の図は、LangChainエージェントの基本的なアーキテクチャを示しています。ユーザーからの入力がエージェント実行器(Agent Executor)に渡され、LLMが思考し、必要に応じてツールを呼び出し、その結果を記憶に保存しつつ、次の行動を決定するプロセスを表しています。
コード解説
以下は、LangChainを使って非常にシンプルなAIエージェントを構築するPythonコードの例です。ここではOpenAIのLLMと、Web検索ツールを組み合わせています。環境変数 OPENAI_API_KEY と SERPAPI_API_KEY が設定されていることを前提とします。
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_core.prompts import PromptTemplate
from langchain_core.messages import HumanMessage, AIMessage
from langchain.memory import ConversationBufferMemory
import os
# 環境変数を設定 (実際には.envファイルなどから読み込むのが一般的)
# os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# os.environ["SERPAPI_API_KEY"] = "YOUR_SERPAPI_API_KEY" # DuckDuckGoSearchRunは不要だが、他の検索ツールで必要になる場合がある
# 1. LLMの初期化
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini")
# 2. ツールの定義
search = DuckDuckGoSearchRun()
tools = [search]
# 3. プロンプトテンプレートの定義
# ReActエージェントは、思考(Thought)と行動(Action)のパターンで動作することを想定したプロンプトが必要です。
prompt_template = PromptTemplate.from_template("""
あなたは役立つAIアシスタントです。
ユーザーの質問に答えるために、以下のツールを使用できます:
{tools}
質問に答えるためにツールを使用する必要がある場合は、以下の形式に従ってください:
Question: ユーザーの質問
Thought: 質問に答えるために何をするべきか考える
Action: 使用するツールと入力。ツールは[{tool_names}]の中から選ぶ。
Action Input: ツールへの入力(JSON形式ではない)
Observation: ツールの結果
...(Thought/Action/Action Input/Observationは必要に応じて繰り返される)
Thought: 最終的な答えが分かった
Final Answer: ユーザーへの最終的な答え
これは、会話の履歴です:
{chat_history}
質問: {input}
Thought:{agent_scratchpad}
""")
# 4. エージェントの作成 (ReActエージェントを使用)
agent = create_react_agent(llm, tools, prompt_template)
# 5. 記憶の初期化
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# 6. Agent Executorの作成
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, memory=memory, handle_parsing_errors=True)
# エージェントの実行
print("AIエージェントを開始します。終了するには'exit'と入力してください。")
while True:
user_input = input("あなた: ")
if user_input.lower() == 'exit':
print("AIエージェントを終了します。")
break
try:
response = agent_executor.invoke({"input": user_input})
print(f"AI: {response['output']}")
except Exception as e:
print(f"エラーが発生しました: {e}")
# エラー発生時にも会話履歴をクリアしないことで、デバッグを容易にする
# 必要であれば memory.clear() を呼び出すことも可能
このコードでは、ユーザーの質問に対し、エージェントが「思考 (Thought)」し、必要であれば「行動 (Action)」として DuckDuckGoSearchRun ツールを呼び出し、「観察 (Observation)」結果を得て、最終的な「答え (Final Answer)」を生成する一連のプロセスが verbose=True によって詳細に表示されます。また、ConversationBufferMemory を使用することで、過去の会話履歴がエージェントの意思決定に影響を与えるようになります。
ポイント
LangChainエージェントは、LLM、Tools、Memory、Agent Executorの連携によって機能します。特にToolsはエージェントの能力を外部世界へ拡張し、Memoryは会話のコンテキストを維持するために不可欠です。Agent Typeの選択は、エージェントの思考プロセスとタスク解決能力に直結します。
3. 高度なAIエージェントの設計と実装戦略
基本的なAIエージェントの構築方法を理解したところで、次にさらに複雑で自律的なシステムを設計するための戦略について掘り下げていきましょう。単一のタスクだけでなく、複数のステップや状況判断を要するシナリオに対応できるエージェントは、ビジネス価値を最大化する上で非常に重要です。
複雑なタスクのためのエージェントチェーンとワークフロー
一つのエージェントがすべての複雑なタスクを直接処理するのではなく、複数のエージェントやチェーンを連携させることで、より堅牢でスケーラブルなシステムを構築できます。LangChainでは、この「エージェントチェーン」の概念が非常に強力です。
- SequentialChain: 複数のチェーンを順番に実行し、前のチェーンの出力を次のチェーンの入力として渡します。データ処理パイプラインのような線形プロセスに適しています。
- RouterChain: ユーザーの入力に基づいて、最適なチェーンまたはエージェントを動的に選択します。例えば、質問が「株価」に関するものであれば株価検索エージェントへ、「天気」に関するものであれば天気予報エージェントへルーティングするといった使い方ができます。
- Agent with tools that are other agents: あるエージェントが、別のエージェント自体をツールとして呼び出すことも可能です。これにより、階層的なエージェント構造を構築し、専門性の高いサブエージェントに特定のタスクを委譲できます。
例えば、顧客サポートのエージェントであれば、まずRouterChainで質問の種類(技術的な問題、請求に関する問い合わせ、一般的な質問)を判別し、それぞれに対応する専門エージェントにタスクを振り分けることで、効率的かつ正確なサポートを提供できます。
エージェントの自律性を高める戦略:自己反省とプランニング
真に自律的なAIエージェントは、単にツールを実行するだけでなく、自身の行動を評価し、必要に応じて計画を修正する能力を持つべきです。この自己反省(Self-Reflection)とプランニング(Planning)のメカニズムは、エージェントのパフォーマンスと信頼性を大幅に向上させます。
- Chain of Thought (CoT): LLMに推論のステップを明示的に出力させることで、思考プロセスを透明化し、より正確な結果を導き出します。LangChainのReActエージェントがこのアプローチを採用しています。
- Self-Correction / Self-Healing: ツール実行結果が期待と異なる場合やエラーが発生した場合、エージェント自身がその原因を分析し、異なるツールやアプローチを試みるよう再計画します。LangChainでは、エラーハンドリングを組み込んだカスタムエージェントや、LLMにエラーメッセージを解析させて次のステップを決定させることで実現できます。
- Plan-and-Execute Agent: まずLLMにタスク全体の大まかな計画(ステップバイステップの実行リスト)を立てさせ、その後、各ステップを個別に実行するエージェントです。これにより、複雑なタスクでも計画から逸脱することなく、着実に進行できます。LangChainの
plan_and_executeモジュールがこれを提供します。
例えば、データ分析エージェントが特定のデータセットからインサイトを抽出する際、まず「データをロードする」「前処理する」「統計分析を行う」「結果を可視化する」といった計画を立て、各ステップでエラーが発生すれば、それを修正しながら進めることで、最終的な目標達成に近づきます。
Human-in-the-Loopの組み込み:安全性と精度を確保
完全に自律的なAIエージェントは魅力的ですが、特に重要な意思決定や倫理的な判断が求められる場面では、人間の介入(Human-in-the-Loop, HITL)が不可欠です。HITLを適切に組み込むことで、エージェントの安全性、精度、信頼性を高めることができます。
- 承認ステップ: エージェントが実行する可能性のある危険なアクション(例: 外部システムへの書き込み、重要なデータの削除)の前に、人間の承認を求めるステップを設けます。
- 曖昧さの解消: LLMがユーザーの意図を完全に理解できない場合や、複数の解釈が可能な場合に、ユーザーに確認を促します。
- 監視とフィードバック: エージェントの動作を常時監視し、異常な挙動や誤った出力があった場合に人間が介入し、フィードバックを与えることでエージェントを改善します。
LangChainでは、カスタムツールとして人間の承認プロセスを組み込んだり、特定の条件でLLMがユーザーに質問を生成するようにプロンプトを設計したりすることで、HITLを実現できます。
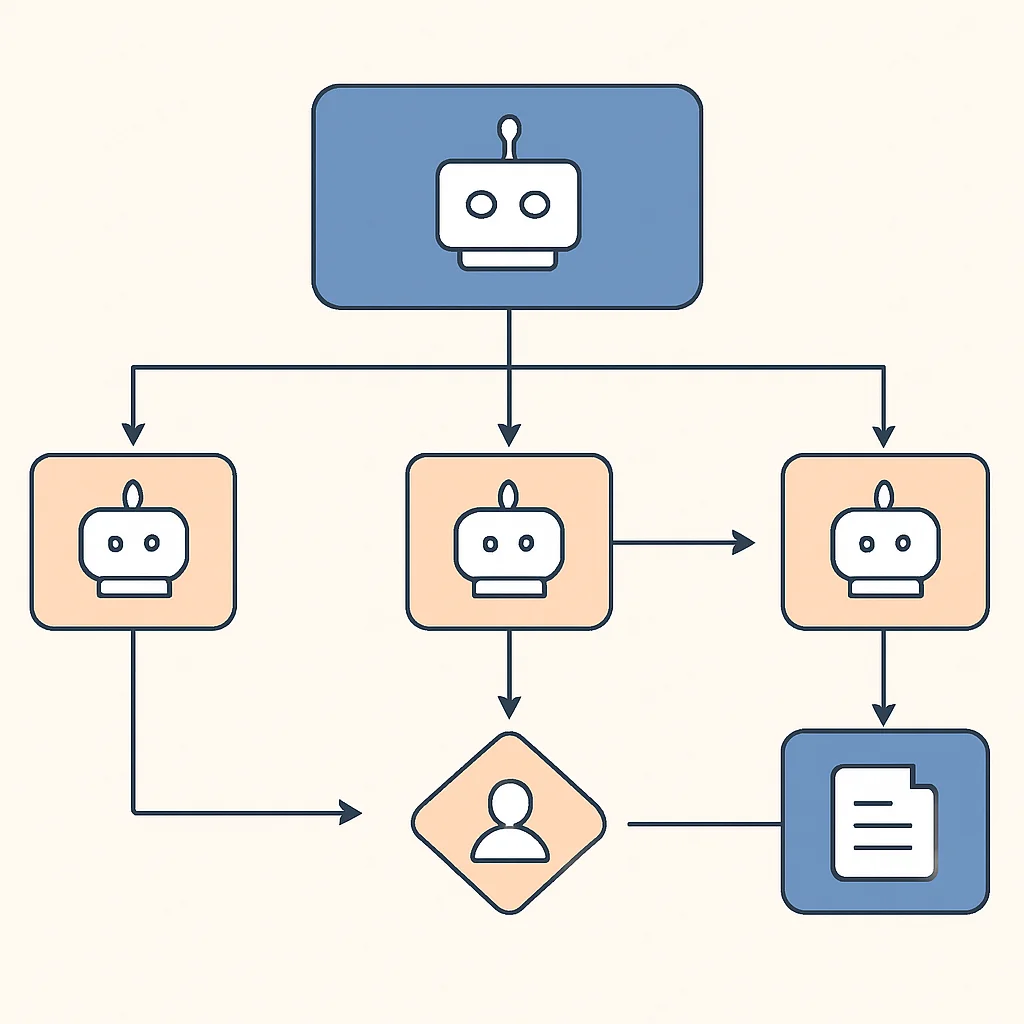
上のフローチャートは、ユーザーからの問い合わせをルーターエージェントが分類し、その後、専門エージェントに振り分け、最終的なアクション実行前に人間による承認ステップを設ける、より高度なエージェントワークフローを示しています。このような設計により、エージェントは複雑なタスクを効率的に処理しつつ、重要な局面での人間の監督を確保できます。
コード解説
ここでは、LangChainの PlanAndExecute エージェントの基本的な構造と、カスタムツールを定義する例を示します。カスタムツールは、特定の条件下で人間の承認を求めるような処理を組み込むことができます。
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_core.prompts import PromptTemplate
from langchain_core.messages import HumanMessage, AIMessage
from langchain.memory import ConversationBufferMemory
from langchain.agents.agent_types import AgentType
from langchain.agents import initialize_agent, AgentExecutor
from langchain.chains import LLMMathChain
from langchain.tools import Tool
import os
# 環境変数を設定 (実際には.envファイルなどから読み込むのが一般的)
# os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini")
# カスタムツール:人間の承認が必要なアクションをシミュレート
def human_approval_tool(action_description: str) -> str:
"""人間による承認が必要なアクションを実行するツール。"""
print(f"\n--- 人間による承認が必要 ---")
print(f"アクションの提案: {action_description}")
response = input("このアクションを承認しますか? (yes/no): ").lower()
if response == "yes":
return "アクションが承認されました。"
else:
return "アクションが拒否されました。タスクを再考してください。"
# 既存のツールとカスタムツールを組み合わせる
tools = [
DuckDuckGoSearchRun(name="Search"),
Tool(
name="Calculator",
func=LLMMathChain.from_llm(llm=llm).run,
description="数学的な計算を行う際に使用します。入力は数値表現の文字列です。"
),
Tool(
name="HumanApproval",
func=human_approval_tool,
description="重要な操作や外部システムへの書き込みなど、人間の承認が必要な場合に呼び出します。入力は実行しようとしているアクションの詳細な説明です。"
)
]
# Plan-and-Executeエージェントの初期化
# このタイプのAgentは、タスクを計画し、その計画を実行するためにツールを使用します。
# 実際には、PlanAndExecuteAgentはより複雑な構造を持つため、ここでは簡易的なエージェントでカスタムツールの利用を示す
# 厳密なPlanAndExecuteAgentの例は、langchain_experimental.plan_and_execute を参照
# ReActベースのエージェントを作成し、HumanApprovalツールを組み込む
# 通常のcreate_react_agentでHumanApprovalツールを利用する
prompt_template_with_approval = PromptTemplate.from_template("""
あなたは役立つAIアシスタントです。
ユーザーの質問に答えるために、以下のツールを使用できます:
{tools}
質問に答えるためにツールを使用する必要がある場合は、以下の形式に従ってください:
Question: ユーザーの質問
Thought: 質問に答えるために何をするべきか考える
Action: 使用するツールと入力。ツールは[{tool_names}]の中から選ぶ。
Action Input: ツールへの入力(JSON形式ではない)
Observation: ツールの結果
...(Thought/Action/Action Input/Observationは必要に応じて繰り返される)
Thought: 最終的な答えが分かった
Final Answer: ユーザーへの最終的な答え
これは、会話の履歴です:
{chat_history}
質問: {input}
Thought:{agent_scratchpad}
""")
agent = create_react_agent(llm, tools, prompt_template_with_approval)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, memory=memory, handle_parsing_errors=True)
# エージェントの実行例
print("AIエージェントを開始します。終了するには'exit'と入力してください。")
while True:
user_input = input("あなた: ")
if user_input.lower() == 'exit':
print("AIエージェントを終了します。")
break
try:
response = agent_executor.invoke({"input": user_input})
print(f"AI: {response['output']}")
except Exception as e:
print(f"エラーが発生しました: {e}")
この例では、HumanApproval というカスタムツールを定義し、エージェントが重要なアクションを実行する前に人間の介入を求める仕組みをシミュレートしています。これにより、エージェントが誤った判断を下すリスクを低減し、安全性を向上させることができます。
ポイント
高度なAIエージェントは、エージェントチェーン、自己反省、プランニングによって自律性を高め、Human-in-the-Loopを組み込むことで安全性と信頼性を確保します。カスタムツールの作成は、エージェントの特定のニーズに応じた機能を拡張する上で非常に強力な手段です。
4. AIエージェント開発における主要な課題とその解決策
AIエージェントの可能性は無限大ですが、その開発にはいくつかの固有の課題が伴います。これらの課題を理解し、適切な解決策を講じることで、より堅牢で信頼性の高いシステムを構築できます。
プロンプトエンジニアリングの難しさとLLMの限界
AIエージェントの動作は、LLMに与えるプロンプトの品質に大きく依存します。しかし、効果的なプロンプトを作成することは難しく、以下のような問題に直面することがあります。
問題 01
プロンプトインジェクションと予期せぬ挙動
悪意のあるユーザーがプロンプトを通じてエージェントの内部指示を上書きしたり、予期せぬ動作をさせたりする可能性があります。また、LLMがプロンプトを誤解し、意図しないツールを呼び出したり、間違った情報を生成したりすることもあります。
解決策
System Promptの強化とGuardrailsの導入: LLMに対して明確な役割と制約を与えるSystem Promptを強力に設定します。また、LangChainの Guardrails や、外部ライブラリ(例: NeMo Guardrails)を使用して、LLMの出力をフィルタリングし、不適切な内容や危険なアクションを阻止します。ユーザー入力のサニタイズも重要です。
問題 02
ハルシネーションと不正確な情報
LLMは「もっともらしい嘘」(ハルシネーション)をつくことがあり、これがエージェントの信頼性を損なう原因となります。特に、ツールからの情報が不十分な場合や、複雑な推論が必要な場合に発生しやすくなります。
解決策
RAG (Retrieval-Augmented Generation) の導入: 外部の信頼できる情報源(データベース、ドキュメントなど)から関連情報を検索し、それをLLMに提示して回答を生成させることで、ハルシネーションを大幅に減らします。LangChainの Retrievers と Vector Stores がこの役割を担います。また、常に情報源を明示することも重要です。
コストとパフォーマンスの最適化
LLMのAPI利用料は、特に大規模なエージェントや頻繁な利用の場合、無視できないコストになります。また、応答速度もユーザーエクスペリエンスに直結します。
問題 03
LLM呼び出しコストとレイテンシの増大
エージェントが複数の思考ステップやツール呼び出しを行うと、LLMへのAPIリクエストが増え、それに伴いコストと応答時間が上昇します。特に高価なモデル(例: GPT-4)を使用する場合、この問題は顕著です。
解決策
モデルの適切な選択とキャッシュ: 複雑な推論が必要ないタスクには、より安価で高速なモデル(例: GPT-3.5 Turbo, GPT-4o Mini)を使用します。LangChainの caching モジュールを利用して、同じ入力に対するLLMの出力をキャッシュすることで、API呼び出し回数を減らし、コストとレイテンシを削減します。また、プロンプトの最適化により、LLMの思考ステップを最小限に抑えることも有効です。
デバッグと監視の重要性
エージェントは複数のコンポーネントが複雑に連携するため、問題発生時の原因特定が難しいことがあります。適切なデバッグと監視の仕組みは不可欠です。

上の画像は、LangChainのデバッグインターフェースの一例で、エージェントがどのような思考プロセスを経て、どのツールを呼び出し、どのような結果を得たかを視覚的に追跡できることを示しています。このようなツールは、複雑なエージェントの挙動を理解し、問題を特定する上で非常に役立ちます。
問題 04
エージェントのブラックボックス化とデバッグの困難さ
LLMの内部動作は不透明な部分が多く、エージェントがなぜ特定の決定を下したのか、どのツールを呼び出したのかを追跡するのが困難な場合があります。これにより、予期せぬエラーや誤動作のデバッグが極めて難しくなります。
解決策
LangSmithの活用と詳細なログ出力: LangChain開発元が提供する LangSmith は、エージェントの実行トレース、LLMの入出力、ツール呼び出し、思考プロセスなどを詳細に可視化し、デバッグとテストを強力に支援します。また、アプリケーションレベルで詳細なログ(verbose=True やカスタムコールバック)を出力し、異常を検知するための監視システムを構築することが重要です。
ポイント
AIエージェント開発では、プロンプトインジェクション対策、ハルシネーション抑制、コスト・パフォーマンス最適化、そしてデバッグ・監視が重要な課題です。RAG、Guardrails、キャッシュ、LangSmithといったツールや戦略を組み合わせることで、これらの課題を克服できます。
5. 実践!LangChainによるAIエージェントの構築事例
これまでの知識を活かし、具体的なユースケースを通じてLangChainでAIエージェントを構築する実践的な方法を見ていきましょう。ここでは、特にビジネスでの応用が期待される「データ分析アシスタントエージェント」を例に挙げます。
ケーススタディ:データ分析アシスタントエージェント
データ分析アシスタントエージェントは、ユーザーが自然言語でデータに関する質問を投げかけると、Pythonのデータ分析ライブラリ(Pandasなど)を駆使してデータを操作・分析し、結果を自然言語で返答するシステムです。これにより、データサイエンティストでなくても、手軽にデータからインサイトを得られるようになります。
ユースケース:データ分析アシスタント
ユーザーがCSVファイルをアップロードし、「売上が最も高い製品は?」「月ごとの売上推移をグラフ化して」といった質問に、エージェントがPythonコードを実行して回答します。
構築ステップ
Step 1
環境準備とライブラリインストール
Python環境をセットアップし、必要なライブラリ(langchain, langchain-openai, pandas, matplotlib, jupyter)をインストールします。特に jupyter は、エージェントがPythonコードを実行する際のサンドボックス環境として利用されるため重要です。
Step 2
LLMとツールの定義
LLMとして ChatOpenAI を、ツールとしてPythonコードを実行できる PythonREPLTool (または create_python_agent で自動生成される PythonAstREPLTool) を定義します。データ分析には pandas ライブラリがデフォルトで利用できるように設定します。
Step 3
エージェントと実行器の初期化
選択したAgent Type(例えば AgentType.OPENAI_FUNCTIONS)と、定義したLLM、ツール、記憶を組み合わせてエージェントを実行器 (AgentExecutor) として初期化します。会話履歴を保持するため ConversationBufferMemory を使用します。
Step 4
データセットの準備と実行
分析対象となるCSVファイル(例: sales_data.csv)を準備し、エージェントに「このファイルを読み込んで分析して」と指示します。エージェントはPythonツールを使ってデータを読み込み、ユーザーの質問に応じて様々な分析を行います。
コード解説
以下は、LangChainでデータ分析アシスタントエージェントを構築するPythonコードの簡略化された例です。このエージェントは、PythonのREPL環境でPandasを使ってデータを操作できます。
import pandas as pd
from langchain_openai import ChatOpenAI
from langchain.agents import create_pandas_dataframe_agent
from langchain.agents.agent_types import AgentType
from langchain.memory import ConversationBufferMemory
import os
# 環境変数を設定
# os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# ダミーのCSVファイルを生成
# 実際のアプリケーションでは、ユーザーがファイルをアップロードする形になります
data = {
'Date': pd.to_datetime(['2026-01-01', '2026-01-02', '2026-01-03', '2026-01-04', '2026-01-05',
'2026-02-01', '2026-02-02', '2026-02-03', '2026-02-04', '2026-02-05']),
'Product': ['A', 'B', 'A', 'C', 'B', 'A', 'C', 'B', 'A', 'C'],
'Sales': [100, 150, 120, 200, 180, 110, 220, 160, 130, 210],
'Region': ['East', 'West', 'East', 'North', 'South', 'East', 'North', 'West', 'South', 'East']
}
df = pd.DataFrame(data)
df.to_csv("sales_data.csv", index=False)
# 1. LLMの初期化
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini")
# 2. Pandas DataFrame Agentの作成
# create_pandas_dataframe_agentは、内部でPythonREPLToolなどを利用し、
# DataFrameを操作するためのプロンプトとツールを自動で設定してくれます。
# verbose=True でエージェントの思考プロセスが見えるようになります。
# memory を渡すことで、会話履歴を保持できます。
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent = create_pandas_dataframe_agent(
llm,
df, # ここでDataFrameをエージェントに渡す
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS, # OpenAI Functionsエージェントタイプを使用
memory=memory
)
# エージェントの実行
print("データ分析AIアシスタントを開始します。終了するには'exit'と入力してください。")
print("分析対象のデータは sales_data.csv です。")
while True:
user_input = input("あなた: ")
if user_input.lower() == 'exit':
print("AIアシスタントを終了します。")
break
try:
response = agent.invoke({"input": user_input})
print(f"AI: {response['output']}")
except Exception as e:
print(f"エラーが発生しました: {e}")
このコードを実行すると、エージェントは sales_data.csv を読み込んだ DataFrame をコンテキストとして持ち、ユーザーの質問に対してPythonコード(Pandas)を生成・実行して回答します。例えば、「総売上はいくらですか?」と尋ねると、エージェントは df['Sales'].sum() のようなコードを実行し、その結果を自然言語で返します。さらに、「月ごとの売上推移を教えて」といったより複雑な質問にも対応可能です。
ポイント
LangChainの create_pandas_dataframe_agent は、データ分析タスクに特化した強力なエージェントを簡単に構築できます。これにより、非技術者でも自然言語でデータと対話し、インサイトを迅速に得ることが可能になります。
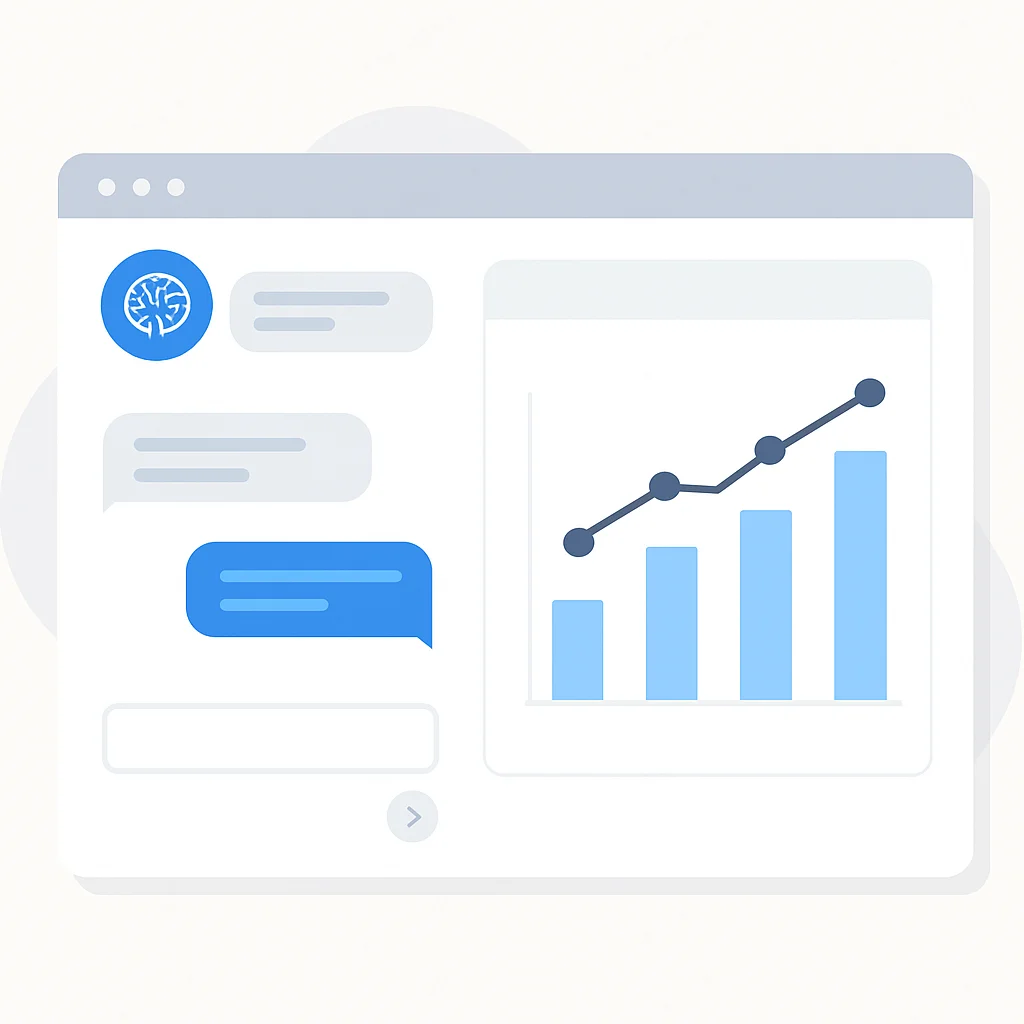
このUIモックアップは、データ分析アシスタントがどのようにユーザーと対話し、質問に基づいてグラフを生成するかの